Party control of the Pennsylvania Senate will be contested this November, especially important in 2020 as the winners will draw the post-Census boundaries.
But that’s in November. Before that, in April’s Primary, we are going to have a rare contested senate race right here in our city. Incumbent Senator Larry Farnese is being challenged by fellow (former) Ward leader Nikil Saval (Saval stepped down from the second to be able to run for this seat). Saval, a co-founder of Reclaim Philadelphia, is presumably trying to win by running to Farnese’s left, a heat check of the recent successes of Larry Krasner and Kendra Brooks.
What are the dynamics at play? Let’s break down Philadelphia’s State Senate PA-1.
View code
library(tidyverse)
library(sf)
library(ggmap)
library(magrittr)
source("../../admin_scripts/util.R")
df_major <- readRDS("../../data/processed_data/df_major_2019-12-03.Rds")
df_major %<>% mutate(warddiv = pretty_div(warddiv))
divs <- st_read("../../data/gis/warddivs/201911/Political_Divisions.shp") %>%
mutate(
warddiv = pretty_div(DIVISION_N),
area = as.numeric(st_area(geometry)) / (1609^2) # mi^2
)wards <- st_read("../../data/gis/warddivs/201911/Political_Wards.shp") %>%
mutate(ward = sprintf("%02d", asnum(WARD_NUM)))sts <- st_read("../../data/gis/state_senate/tigris_upper_house_2015.shp") %>%
st_transform(4326)sts_1 <- sts %>% filter(SLDUST == "001")
expand <- function(x, factor){
mean_x <- mean(x)
return(mean_x + factor * (x - mean_x))
}
expand_bb <- function(bb, factor){
bb[c(1,3)] <- expand(bb[c(1,3)], factor)
bb[c(2,4)] <- expand(bb[c(2,4)], factor)
bb
}
st_bbox <- function(obj, expand, ...){
bb <- sf::st_bbox(obj, ...)
bb %<>% expand_bb(expand)
names(bb) <- c("left", "bottom", "right", "top")
bb
}
bb <- st_bbox(sts_1, expand=1.2)
basemap <- ggmap::get_stamenmap(
bbox=bb,
zoom = 12,
maptype="toner-lite"
)
get_labpt_df <- function(sf){
df <- st_centroid(sf) %>%
mutate(
x=sapply(geometry, "[", 1),
y=sapply(geometry, "[", 2)
) %>%
as.data.frame() %>%
select(-geometry)
return(df)
}
district_map <- ggmap(
basemap,
extent="device",
base_layer = ggplot(sts),
maprange = FALSE
) +
theme_map_sixtysix() %+replace%
theme(legend.position = c(0.8, 0.2))The geography of PA-1
[Reminder: You can make all of these maps and more on the Ward Portal!]
PA-1 covers most of South Philly (minus Point Breeze), Center City, and reaches North into Brewerytown, Kensington, and Port Richmond. Both of the candidates were until recently Ward Leaders in the district: Farnese still is in West Center City’s 8th Ward, and Saval was in Queen Village’s 2nd until resigning to run for this seat.
View code
phila_whole <- st_union(wards)
bb_phila <- st_bbox(phila_whole, 1.2)
ggplot(phila_whole) +
geom_sf(fill=strong_green, color=NA, alpha=0.4) +
geom_sf(
data=st_crop(sts, bb_phila),
fill=strong_green, color = "white", size = 1, alpha=0.3
) +
geom_sf(
data=sts %>% filter(SLDUST == "001"),
fill=strong_green, color = "white", size = 1
) +
geom_sf_text(
data = st_crop(sts, bb_phila),
aes(label=asnum(SLDUST))
) +
ggtitle("State Senate Districts") +
theme_map_sixtysix() %+replace%
theme(panel.grid.major = element_blank())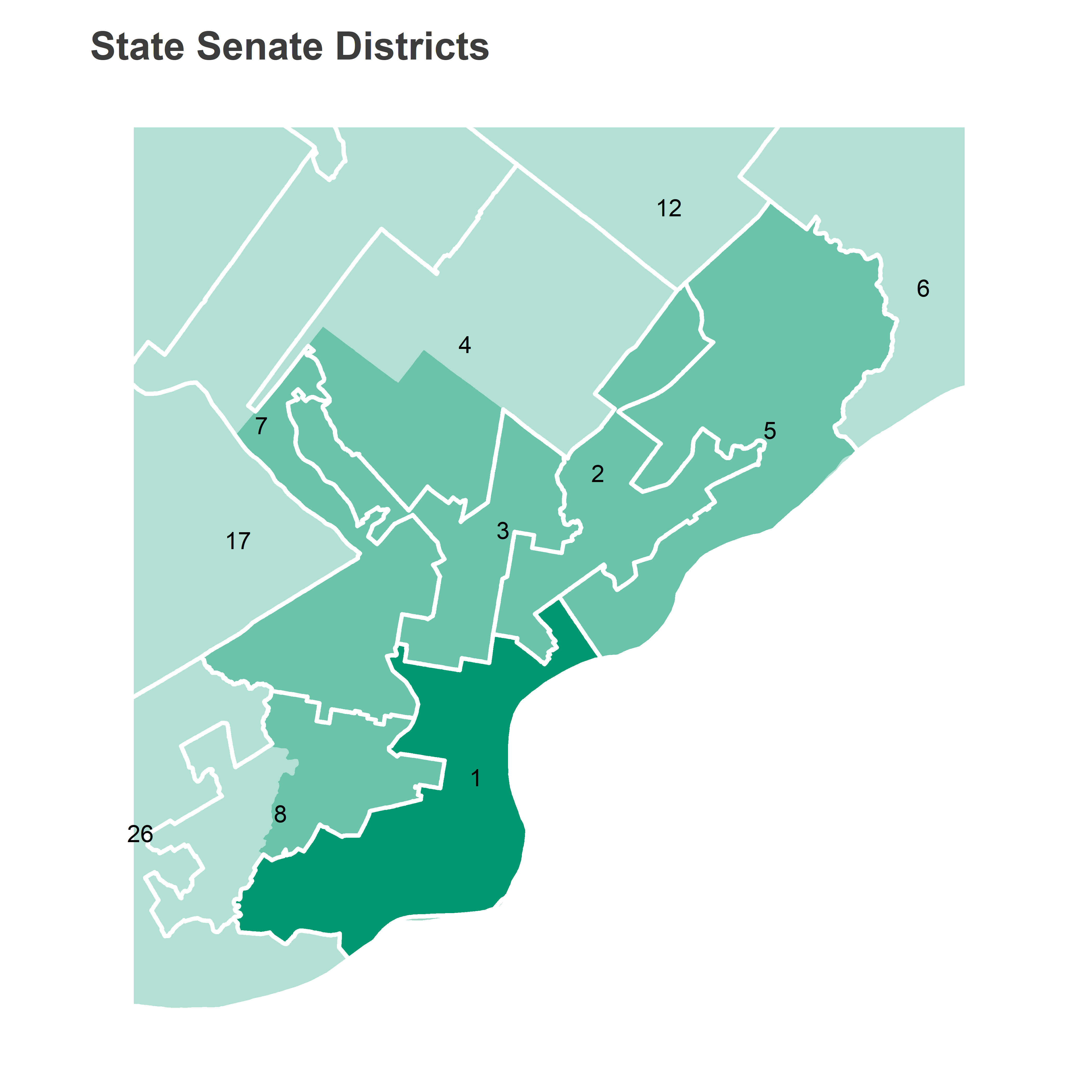
View code
divs$sts <- divs %>%
st_centroid() %>%
st_covered_by(sts) %>%
(function(x){sts$SLDUST[unlist(x)]})
district <- "001"
district_map +
geom_sf(
data = wards %>% filter(ward %in% c("02", "08")),
fill="black",
alpha = 0.5,
color=NA
) +
geom_sf(
aes(alpha = (SLDUST == district)),
fill="black",
color = "grey50",
size=2
) +
geom_sf_text(
data=wards %>% filter(ward %in% c("02", "08")),
aes(label = sprintf("Ward %i", asnum(ward))),
color="white"
) +
scale_alpha_manual(values = c(`TRUE` = 0.2, `FALSE` = 0), guide = FALSE) +
ggtitle(sprintf("State Senate District %s", asnum(district)))
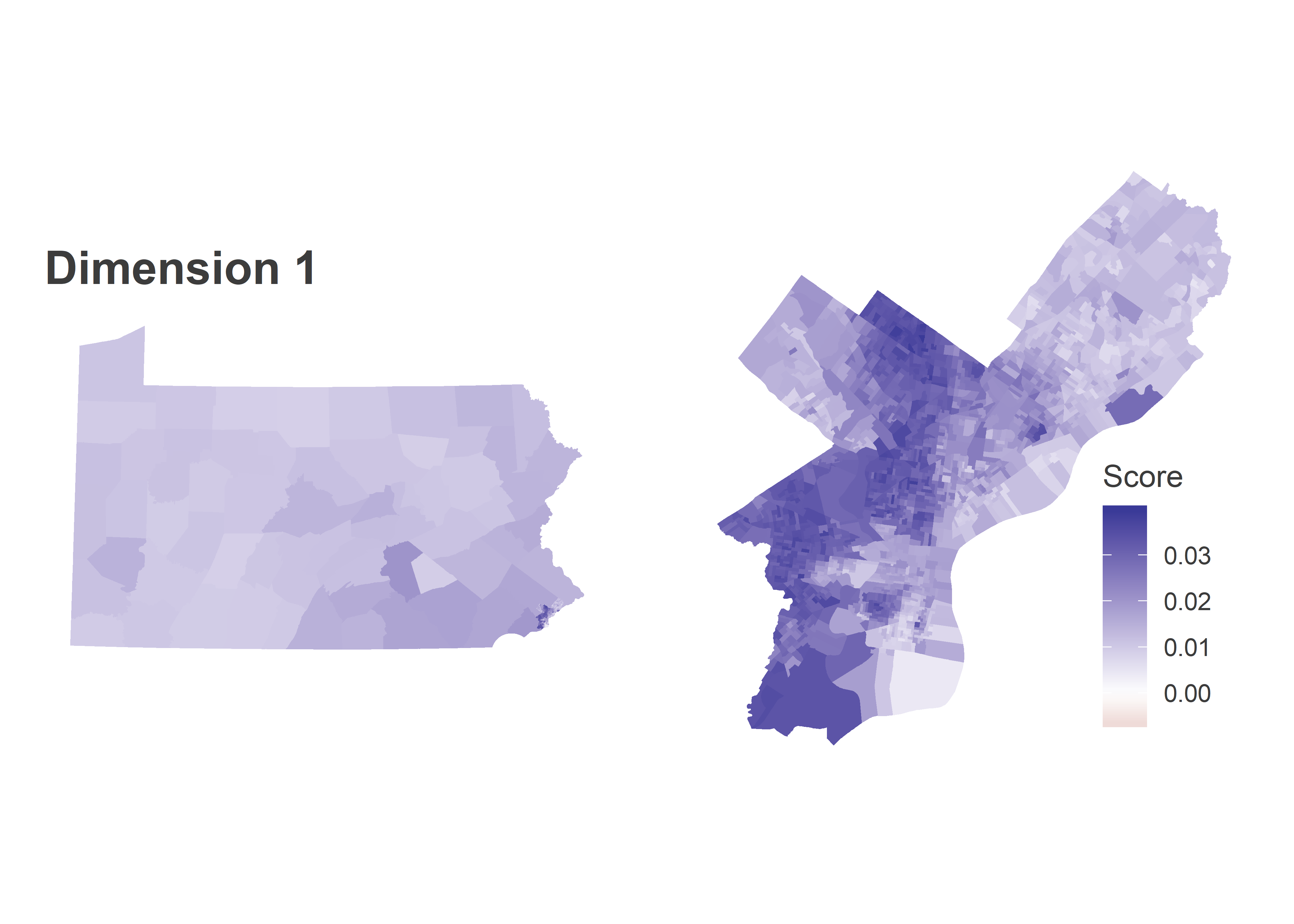
The vast majority of the district’s votes come from Center City, South Philly, and Fairmount, which represented the highest-turnout neighborhoods in the entire city in November’s General.
View code
turnout <- df_major %>%
filter(is_topline_office) %>%
group_by(warddiv, year, election) %>%
summarise(turnout = sum(votes))
maxval <- 20e3
labelmax <- function(x, max) {
ifelse(
x == max,
paste0(scales::comma(x), "+"),
scales::comma(x)
)
}
district_map +
geom_sf(
data=divs %>%
left_join(
turnout %>% filter(year == 2019, election == "general")
),
aes(fill = pmin(turnout/area, maxval)),
color=NA,
alpha=0.8
) +
geom_sf(
data=st_crop(sts, bb_phila),
fill=NA,
color="white",
size=2
) +
scale_fill_viridis_c(
"Votes/\n mile^2",
labels=function(x) labelmax(x, maxval)
) +
ggtitle("Votes in the 2019 General")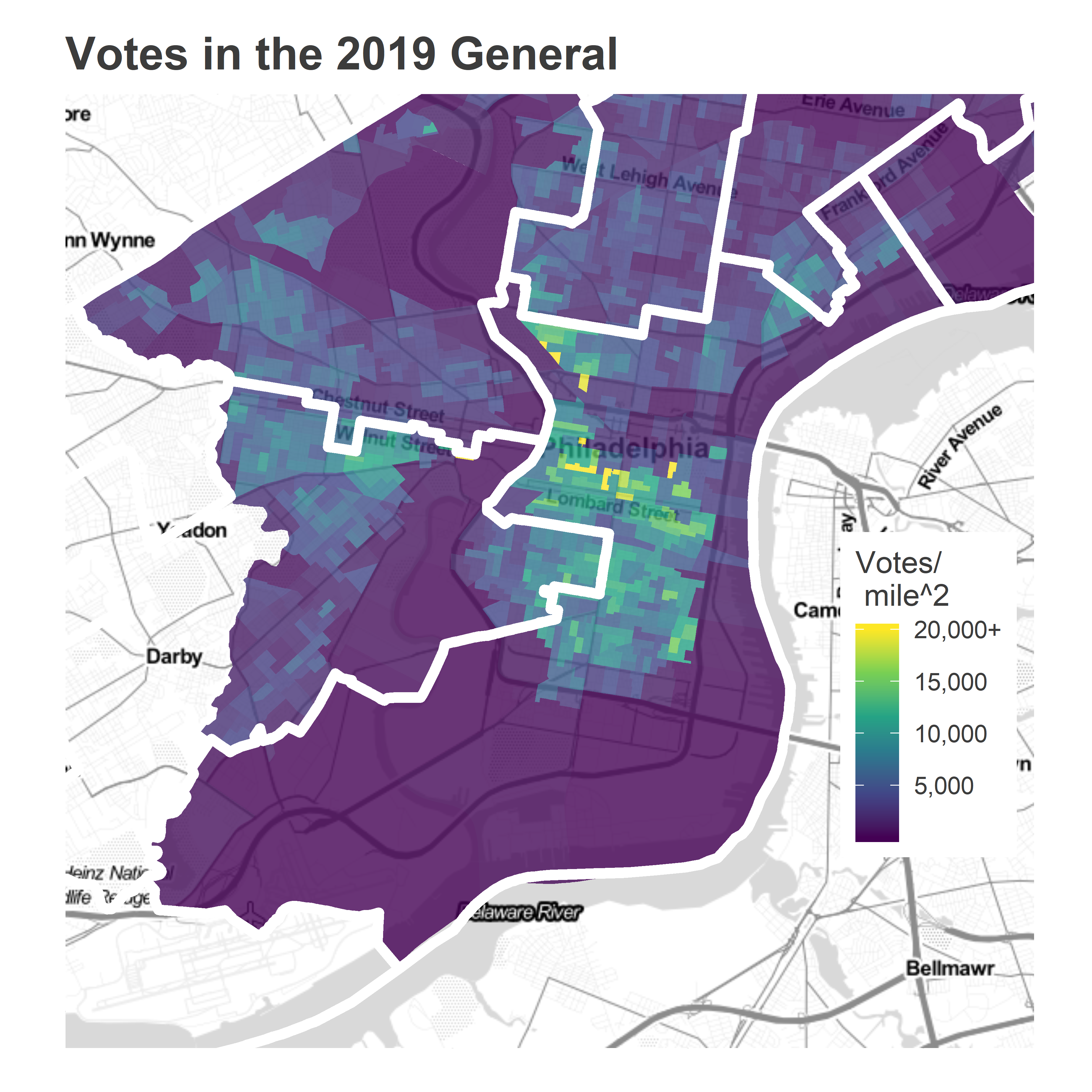
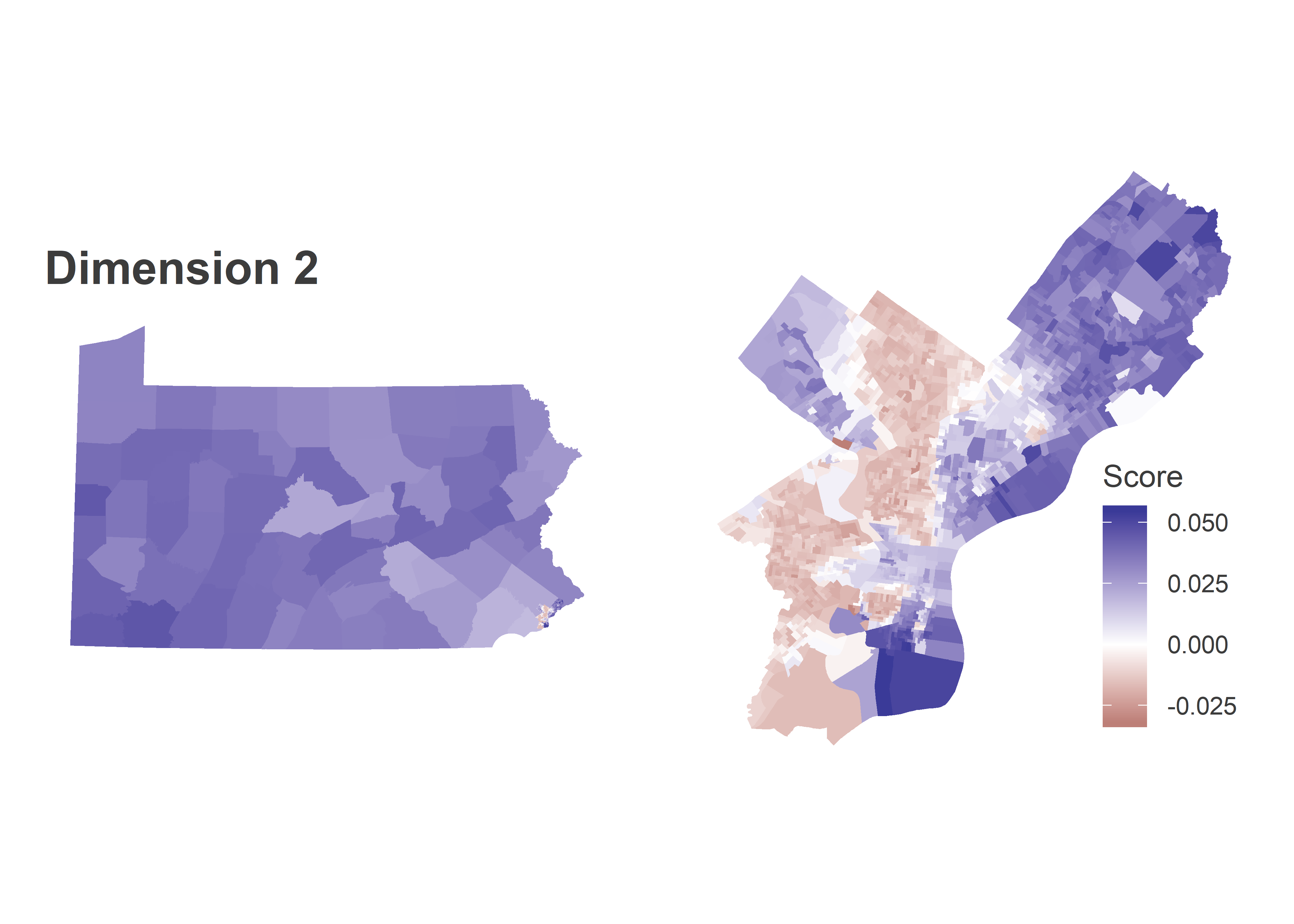
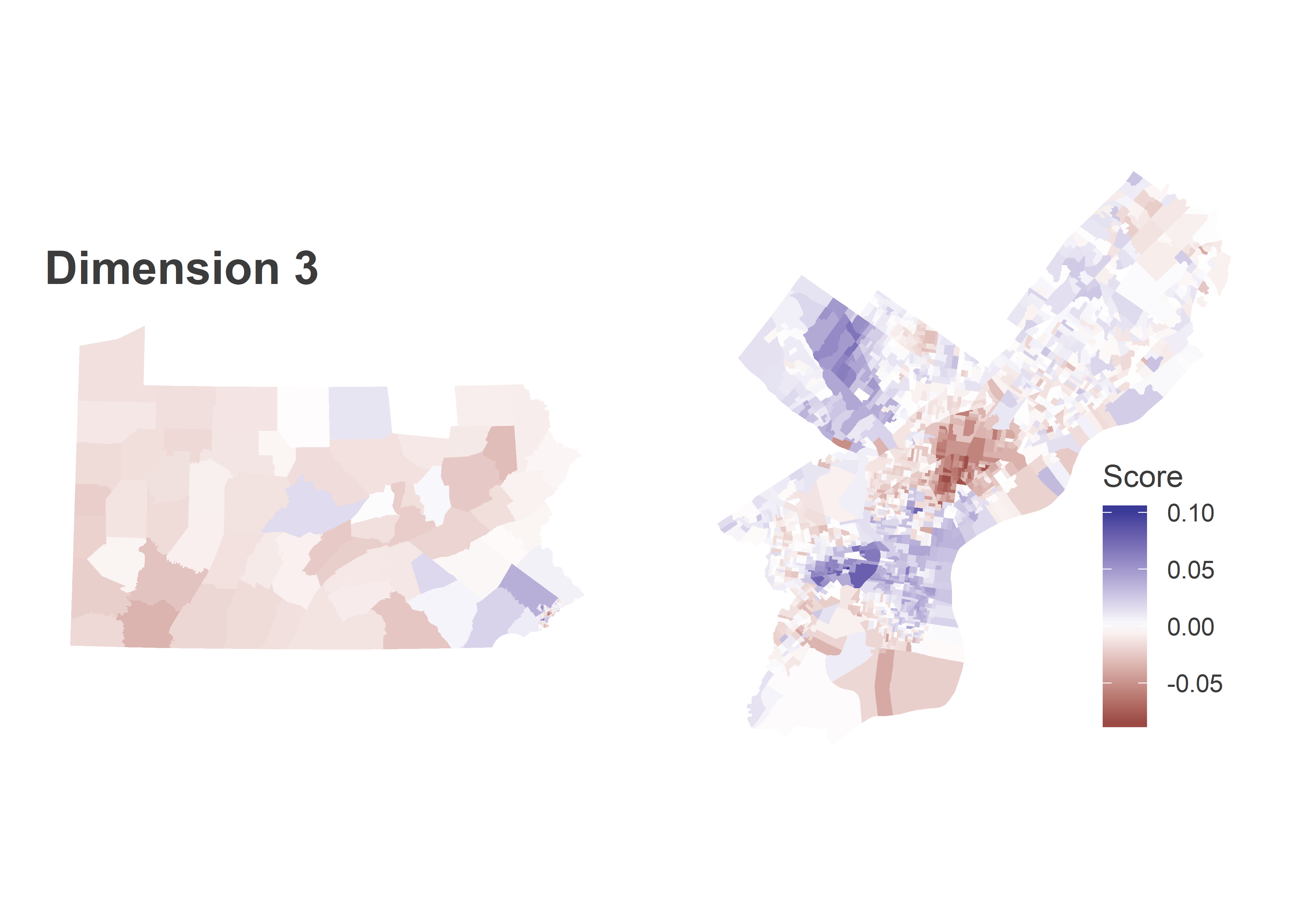
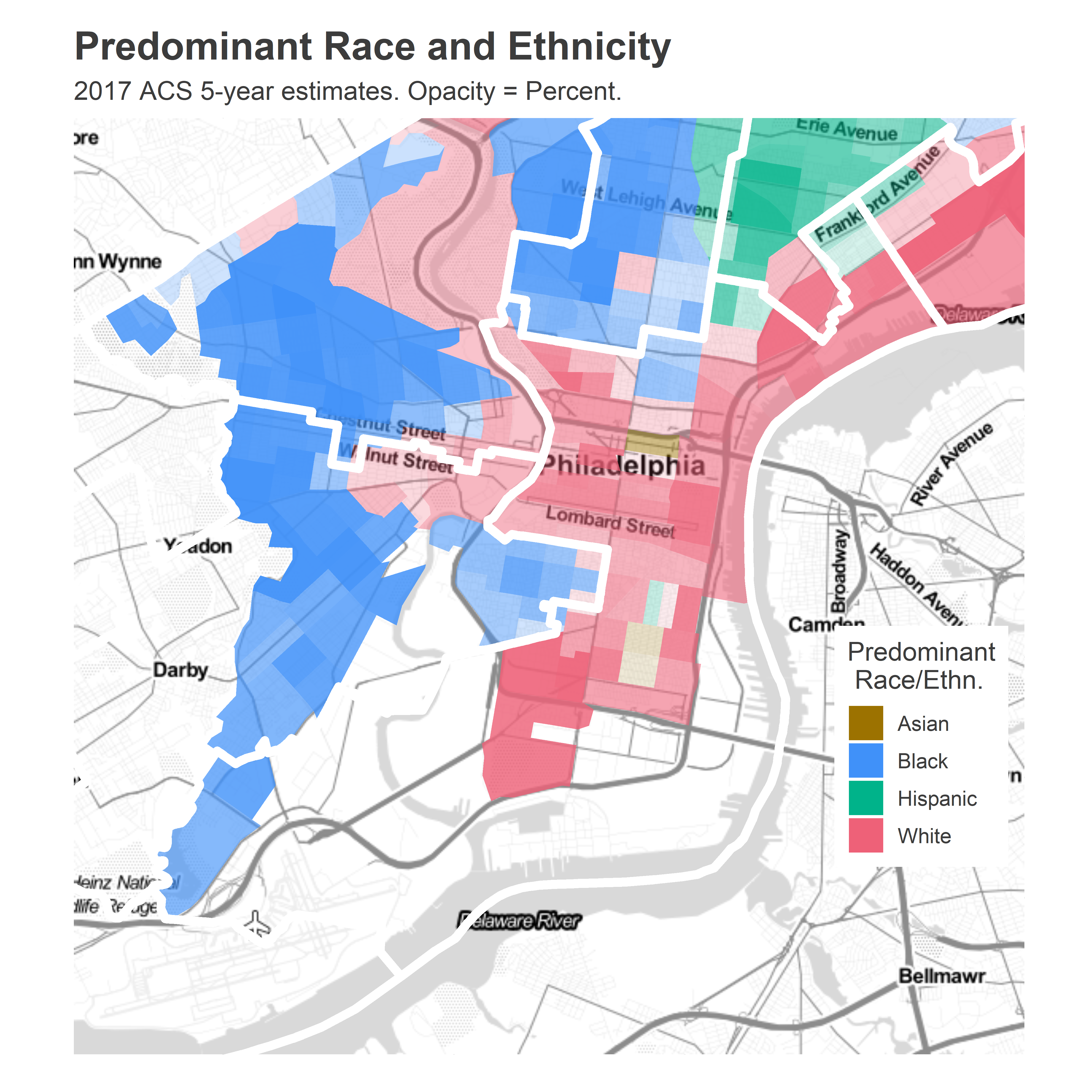
The district’s residents are mostly White: the ACS 2017 estimates have the district 61% White, 13% Black, 12% Asian, and 11% Hispanic. The boundaries manage to almost perfectly gerrymander out the predominantly-Black neighborhoods of Point Breeze, carving out below Washington, above Passyunk, and West of Broad; and North Philly, running along the racial boundary of Girard.
View code
census <- read_csv("../../data/census/acs_2013_2017_phila_bg_race_income.csv")
maxpop_name <- function(wht, blk, hisp, asn){
maxes <- apply(cbind(wht, blk, hisp, asn), 1, which.max)
maxes <- sapply(maxes, function(x) if(length(x) == 1) x else NA)
c("white", "black", "hispanic", "asian")[maxes]
}
maxpop_val <- function(wht, blk, hisp, asn){
apply(cbind(wht, blk, hisp, asn), 1, max)
}
census <- census %>%
mutate(tract = substr(as.character(Geo_FIPS), 1, 11)) %>%
group_by(tract) %>%
summarise_at(
vars(starts_with("pop_")),
funs(sum)
) %>%
mutate(pop_total = pop_hisp + pop_nh) %>%
mutate(
pwht = pop_nh_white / pop_total,
pblk = pop_nh_black / pop_total,
phisp = pop_hisp / pop_total,
pasn = pop_nh_asian / pop_total
) %>%
mutate(
maxpop = maxpop_name(pwht, pblk, phisp, pasn),
maxpop_val = maxpop_val(pwht, pblk, phisp, pasn)
)
tracts <- st_read("../../data/gis/census/cb_2015_42_tract_500k.shp") %>%
filter(COUNTYFP == "101") %>%
st_transform(4326) %>%
left_join(census, by=c("GEOID" = "tract"))district_map +
geom_sf(
data=tracts %>%
filter(!is.na(maxpop_val)) %>%
mutate(maxpop = format_name(maxpop)),
aes(
fill=maxpop,
alpha = 100 * maxpop_val
),
color=NA
) +
geom_sf(
data=st_crop(sts, bb_phila),
fill=NA,
color="white",
size=2
) +
scale_alpha_continuous(
range=c(0, 1),
guide=FALSE
) +
scale_fill_manual(
"Predominant\n Race/Ethn.",
values = c(
Black = light_blue,
White = light_red,
Hispanic = light_green,
Asian = strong_orange
)
) +
ggtitle(
"Predominant Race and Ethnicity",
"2017 ACS 5-year estimates. Opacity = Percent."
)
PA-1’s recent elections
Farnese hasn’t been plausibly challenged since 2008, when he won the seat vacated by indicted Senator Vince Fumo.
Ironically, Farnese won that race on the votes of Center City’s wealthy progressives, edging out Johnny Doc 43% to 38% (candidate Anne Dicker won the last 19%).
View code
sts_2008 <- df_major %>%
filter(
election == "primary", party == "DEMOCRATIC",
year == 2008, office == "SENATOR IN THE GENERAL ASSEMBLY",
district == 1
) %>%
group_by(ward, candidate) %>%
summarise(votes = sum(votes)) %>%
group_by(ward) %>%
mutate(
total_votes = sum(votes),
pvote=100 * votes/total_votes,
candidate=format_name(candidate),
is_winner = rank(desc(pvote)) == 1,
margin = pvote - pvote[rank(desc(pvote)) == 2]
)
district_map +
geom_sf(
data = st_intersection(wards, sts_1) %>%
inner_join(sts_2008 %>% filter(is_winner)),
aes(fill=candidate, alpha=margin),
color=NA,
) +
scale_fill_manual(
"Winner",
values=c(light_green, light_purple)
) +
scale_alpha_continuous("Margin (%)") +
theme(legend.box = "vertical") +
ggtitle("The 2008 PA-1 Democratic Primary")
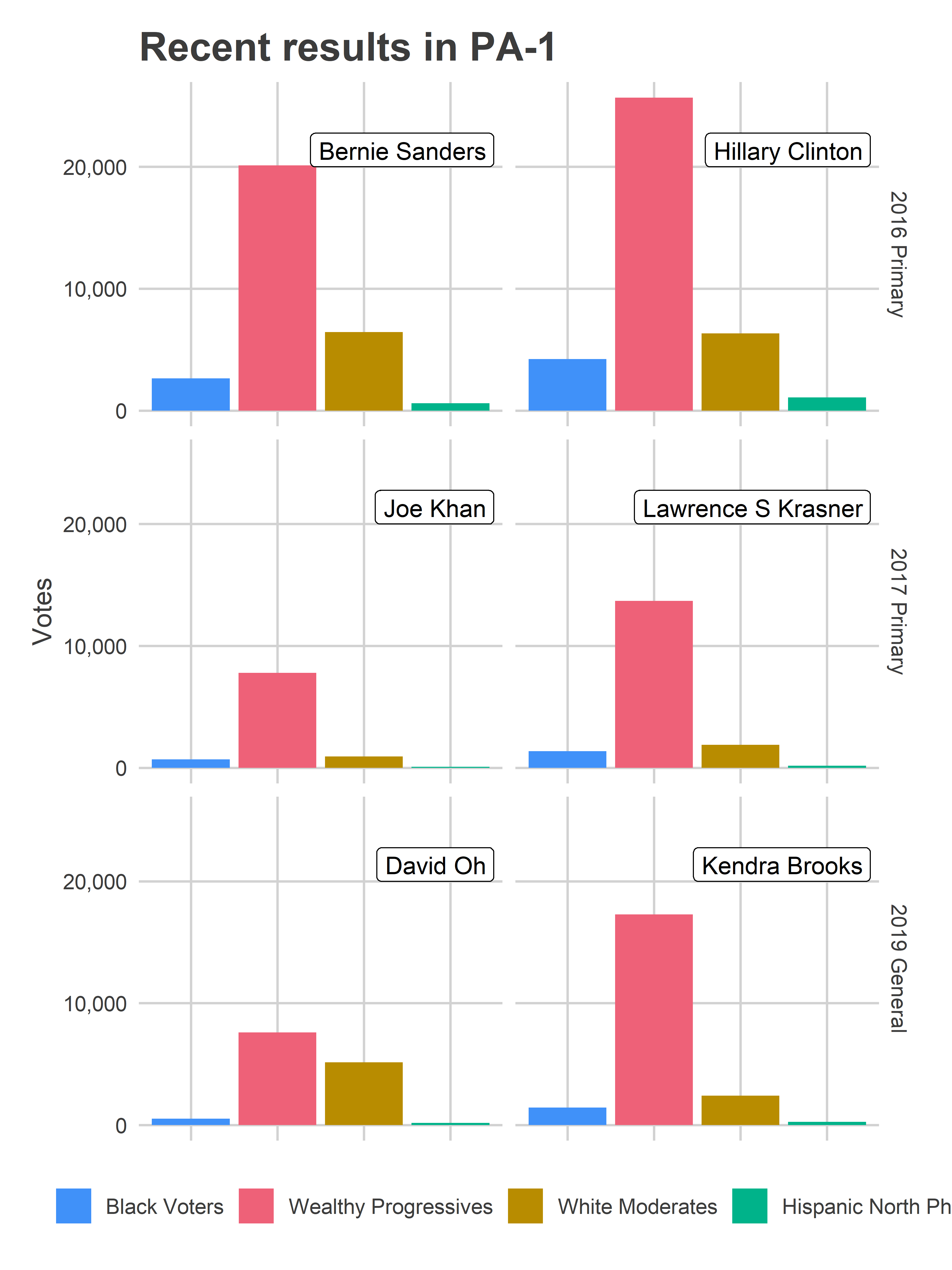
Those progressive districts have only become more influential. In more recent elections, the district has run significantly more progressive than the city as a whole. Bernie Sanders performed 7 percentage points better than in the city as a whole (though still lost the district to Clinton), Krasner 6 pp better, and Brooks 1.6 pp.
View code
races <- tribble(
~year, ~election, ~office, ~short_office, ~candidates,
"2016", "primary", "PRESIDENT OF THE UNITED STATES", "President", list("HILLARY CLINTON", "BERNIE SANDERS"),
"2017", "primary", "DISTRICT ATTORNEY", "District Attorney",list("LAWRENCE S KRASNER", "JOE KHAN"),
"2019", "general", "COUNCIL AT LARGE", "City Council", list("KENDRA BROOKS", "DAVID OH")
)
div_cats <- readRDS("../../data/processed_data/div_cats_2019-12-03.RDS")
divs %<>% left_join(div_cats)
df_cand <- df_major %>%
inner_join(races) %>%
filter(election == "general" | party == "DEMOCRATIC") %>%
left_join(divs %>% as.data.frame() %>% select(warddiv, sts, cat)) %>%
group_by(warddiv, year, office) %>%
mutate(total_votes = sum(votes), pvote=100 * votes/total_votes) %>%
filter(mapply(`%in%`, candidate, candidates))
df0 <- df_cand %>%
group_by(candidate, year, election, short_office) %>%
summarise(
pvote_city = weighted.mean(pvote, total_votes),
pvote_sts01 = weighted.mean(pvote, ifelse(sts == "001", total_votes, 0))
) %>%
ungroup()
df0 %>%
mutate(candidate = format_name(candidate)) %>%
arrange(year) %>%
mutate(election = paste(year, format_name(election))) %>%
select(election, candidate, pvote_city, pvote_sts01) %>%
knitr::kable(digits=1, col.names=c("Election", "Candidate", "City %", "PA-1 %"))| Election | Candidate | City % | PA-1 % |
|---|---|---|---|
| 2016 Primary | Bernie Sanders | 37.0 | 44.2 |
| 2016 Primary | Hillary Clinton | 62.6 | 55.3 |
| 2017 Primary | Joe Khan | 20.3 | 24.7 |
| 2017 Primary | Lawrence S Krasner | 38.2 | 44.6 |
| 2019 General | David Oh | 4.0 | 4.5 |
| 2019 General | Kendra Brooks | 4.5 | 7.1 |
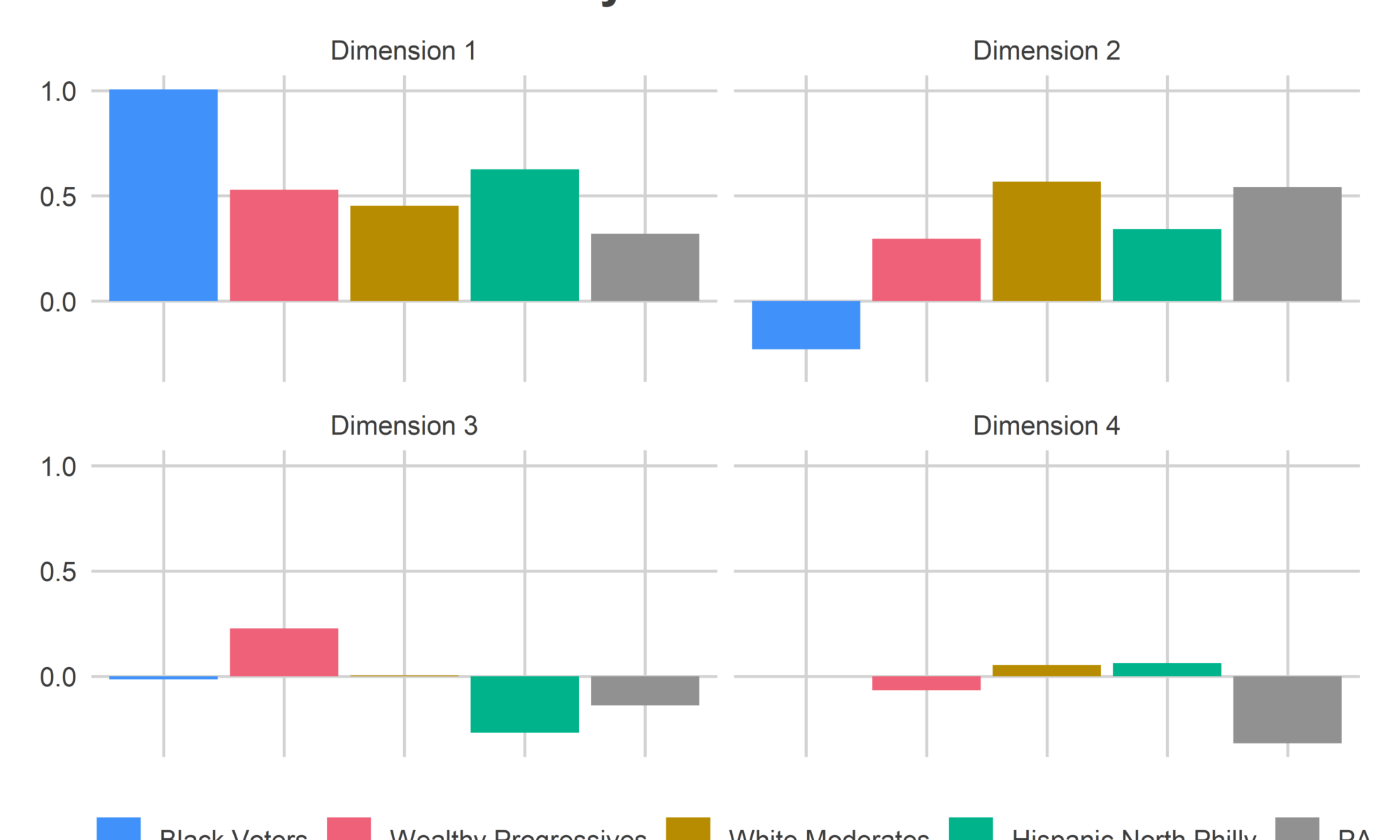
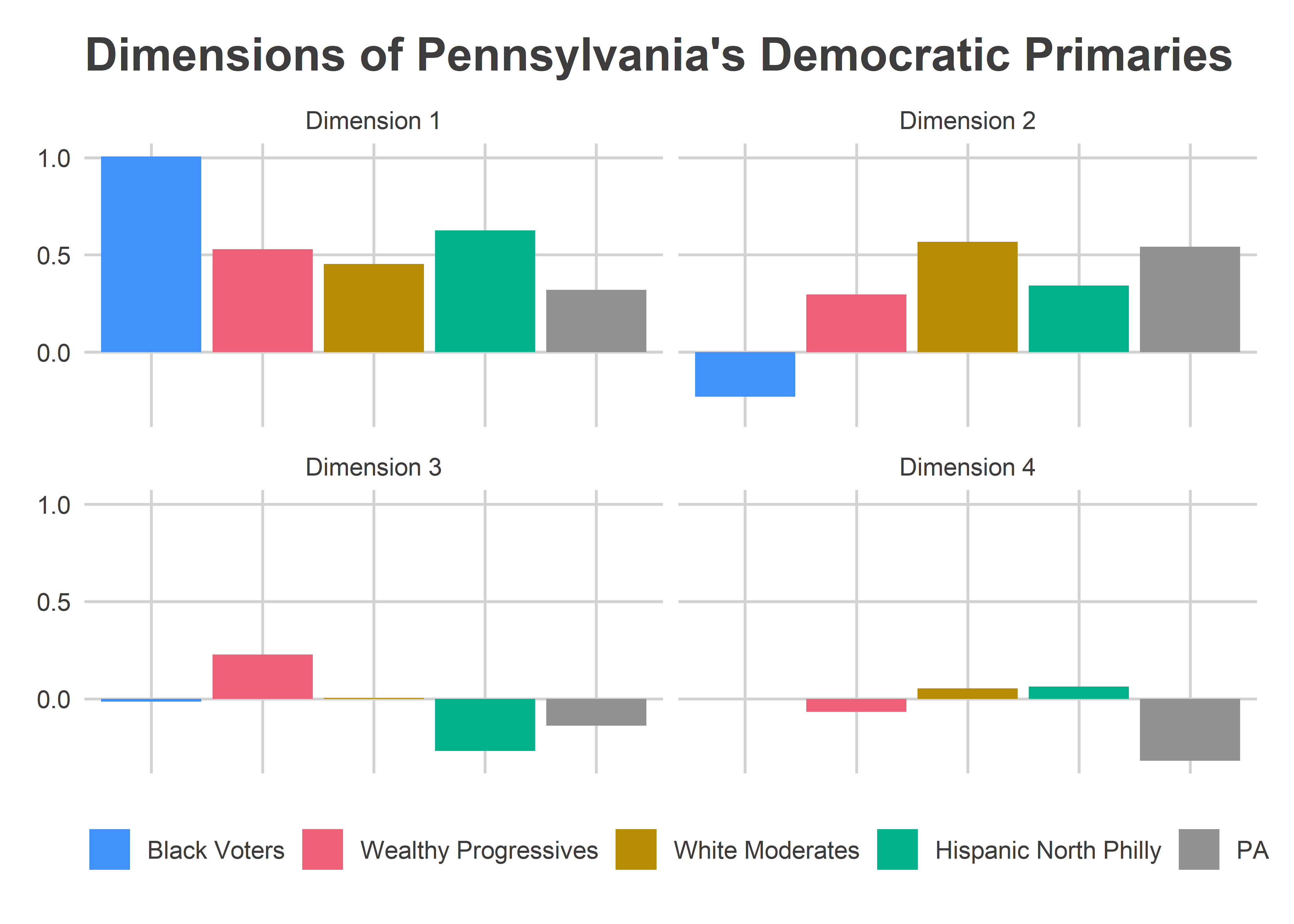
Revisit Philadelphia’s Voting Blocs. The district is mage up mostly of Wealthy Progressive and White Moderate divisions.
View code
bloc_colors <- c(
"Black Voters" = light_blue,
"Wealthy Progressives" = light_red,
"White Moderates" = light_orange,
"Hispanic North Philly" = light_green
)
district_map +
geom_sf(
data=divs,
aes(fill = cat),
color=NA,
alpha=0.8
) +
geom_sf(
data=st_crop(sts, bb_phila),
fill=NA,
color="white"
) +
scale_fill_manual(
"Voting Bloc",
values=bloc_colors
) +
ggtitle("Voting Blocs of PA-1")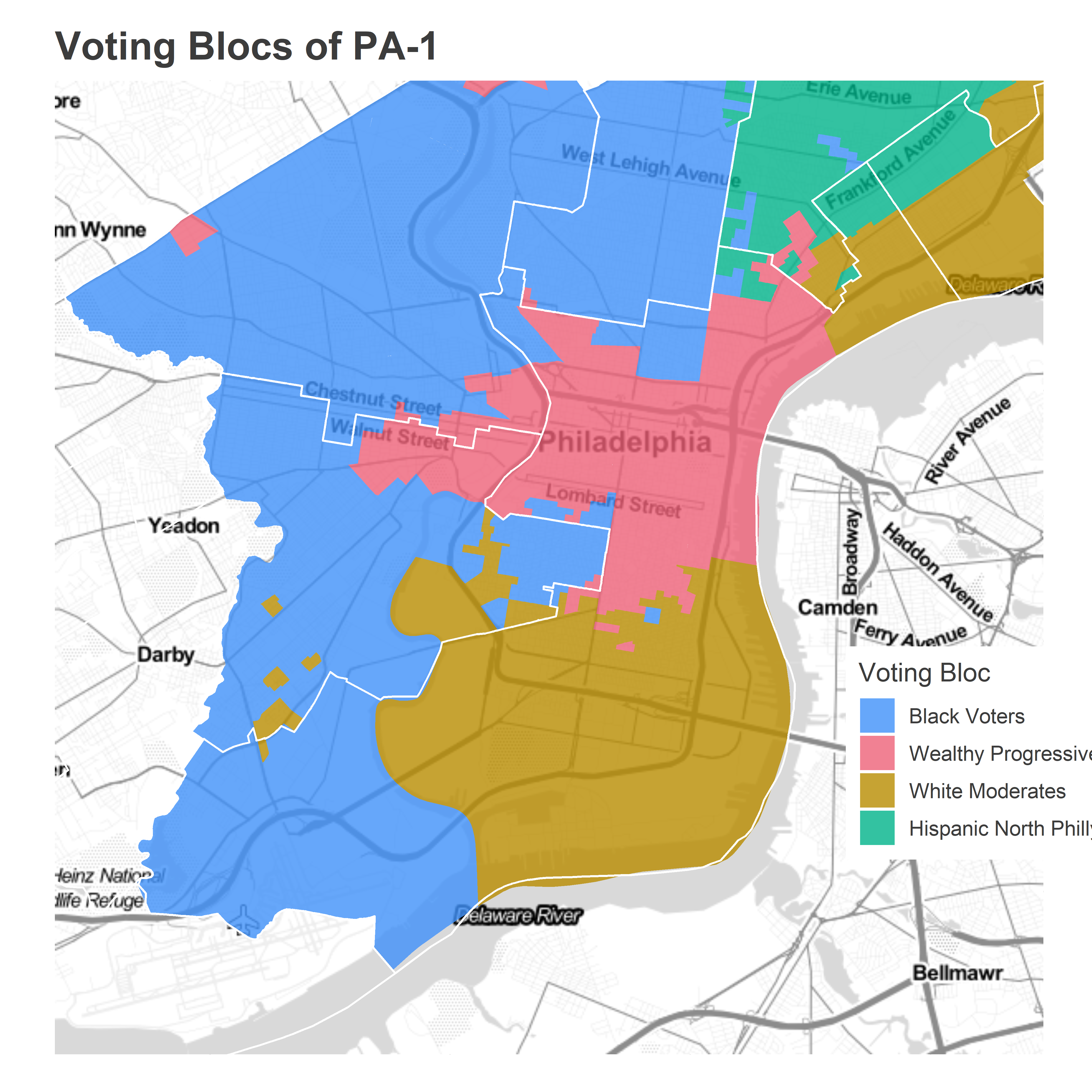
(Notice that my blocs based on voting patterns don’t perfectly match the Census populations; my Black Voter bloc extends above Washington Ave and the Census population doesn’t. That’s because the blocs are based on all elections back to 2002, while the Census data is more recent. That’s an emergent boundary that’s moving South as Point Breeze gentrifies.)
View code
turnout_nums <- turnout %>%
filter(year %in% c(2016, 2017, 2019)) %>%
ungroup() %>%
inner_join(
divs %>%
filter(sts == "001")
) %>%
group_by(year,election,cat) %>%
summarise(turnout = sum(turnout)) %>%
group_by(year, election) %>%
mutate(pturnout = turnout / sum(turnout)) %>%
as.data.frame()The Wealthy Progressives cast 67% of the votes in the 2016 Primary, 73% in the 2017 Primary, and 68% in the 2019 General. Their votes drive the overall results of the district.
View code
cand_nums <- df_cand %>%
group_by(year, election, short_office) %>%
mutate(candnum = as.numeric(factor(candidate))) %>%
select(year, election, short_office, candidate, candnum) %>%
unique()
ggplot(
df_cand %>%
ungroup() %>%
filter(sts == "001") %>%
group_by(candidate, year, election, short_office, cat) %>%
summarise(votes = sum(votes)) %>%
left_join(cand_nums)
) +
geom_bar(
aes(x = cat, y = votes, fill=cat),
stat="identity"
) +
scale_fill_manual(NULL, values=bloc_colors) +
facet_grid(paste(year, format_name(election)) ~ candnum) +
geom_label(
data=cand_nums,
aes(label=format_name(candidate)),
x = 4.5, y=20e3,
hjust=1,
vjust=0
) +
scale_y_continuous("Votes", labels = scales::comma) +
theme_sixtysix() %+replace%
theme(
strip.text.x = element_blank(),
axis.text.x = element_blank()
) +
labs(
title="Recent results in PA-1",
x=NULL
)
The recent left-wing support comes slightly more from the gentrifying ring around Center City than from Center City itself, while deeper South Philly and Northern Kensington and Port Richmond remain more conservative.
View code
district_map +
geom_sf(
data=divs %>%
left_join(df_cand) %>%
# left_join(office_max) %>%
left_join(cand_nums) %>%
group_by(year, election, short_office, warddiv) %>%
mutate(pvote_head2head = 100 * pvote / sum(pvote)),
aes(fill=pvote_head2head),
color=NA,
alpha=0.8
) +
geom_sf(
data=st_crop(sts, bb_phila),
fill=NA,
color="white"
) +
geom_label(
data = cand_nums,
aes(label=format_name(candidate)),
hjust=1.1,
vjust=1,
x = bb["right"],
y = bb["top"]
) +
facet_grid(year + election ~ candnum) +
theme(
strip.text.x = element_blank(),
legend.position = "right"
) +
scale_fill_viridis_c("Head-to-head\n % of Vote") +
ggtitle("Recent Elections in PA-1", "Head-to-head Vote Percentages")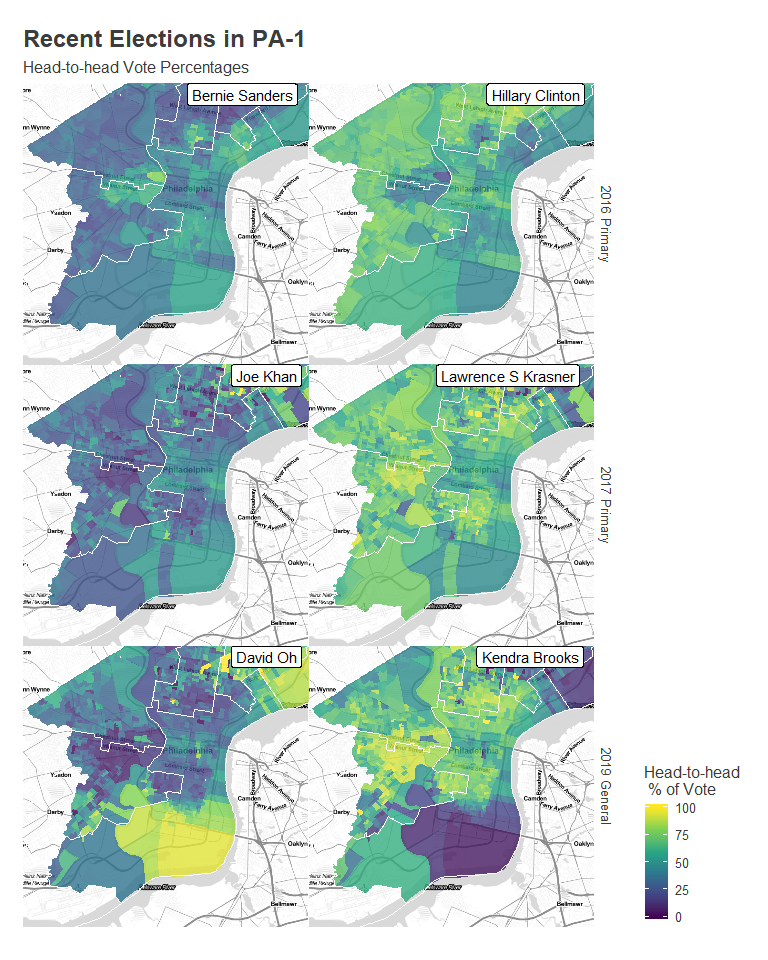
Farnese vs Saval in April
This race will test a dynamic that the city hasn’t really tested yet in the post-2016 world: a candidate who historically has performed well among Wealthy Progressive divisions being challenged from the left.
Because of that, it’s hard to use past elections to predict this one. There aren’t easily predictable fault-lines, the way there were in 2019’s Council races for District 2 and District 3.
But let’s assume Farnese does better than Saval in the White Moderate and Black Voter divisions, maybe by a gap of 70-30. And assume that the Wealthy Progressive divisions again make up 70% of the vote. Saval would need to win the Wealthy Progressives by 59 – 41 to win the district. That’s a steep challenge, but we’ve seen steep challenges overcome in recent months.
View code
prop_wealthy_progressive <- 0.7
line_slope <- -prop_wealthy_progressive / (1-prop_wealthy_progressive)
y_intercept <- 0.5 / (1-prop_wealthy_progressive)
cand_scatter <- df_cand %>%
ungroup() %>%
filter(sts == "001") %>%
mutate(
is_wealthy = ifelse(
cat == "Wealthy Progressives", "wealthyprogs", "other"
)
) %>%
group_by(candidate, year, election, short_office, is_wealthy) %>%
summarise(votes = sum(votes)) %>%
group_by(year, election, short_office, is_wealthy) %>%
mutate(pvote_h2h = votes / sum(votes)) %>%
ungroup() %>%
select(year, election, short_office, candidate, is_wealthy, pvote_h2h) %>%
spread(key=is_wealthy, value=pvote_h2h)
ggplot(
cand_scatter,
aes(x = 100*wealthyprogs, y=100*other)
) +
geom_label(aes(label = format_name(candidate))) +
geom_abline(
slope = line_slope,
intercept = 100 * y_intercept,
linetype="dashed"
) +
coord_fixed() +
xlim(c(0,100)) +
ylim(c(0, 100)) +
annotate(
"text",
y=0,
# x=-100*y_intercept/line_slope,
x=0,
label=sprintf("Assuming Wealthy Progressives have %s%% of turnout.\nCandidates are at their head-to-head percentages.", round(100*prop_wealthy_progressive)),
hjust=0,
vjust=-0.1,
color="grey50"
) +
labs(
title="Win Line for PA-1",
subtitle="Candidates to the top-right win.",
x="Percent in Wealthy Progressive divisions",
y="Percent in other divisions"
) +
theme_sixtysix()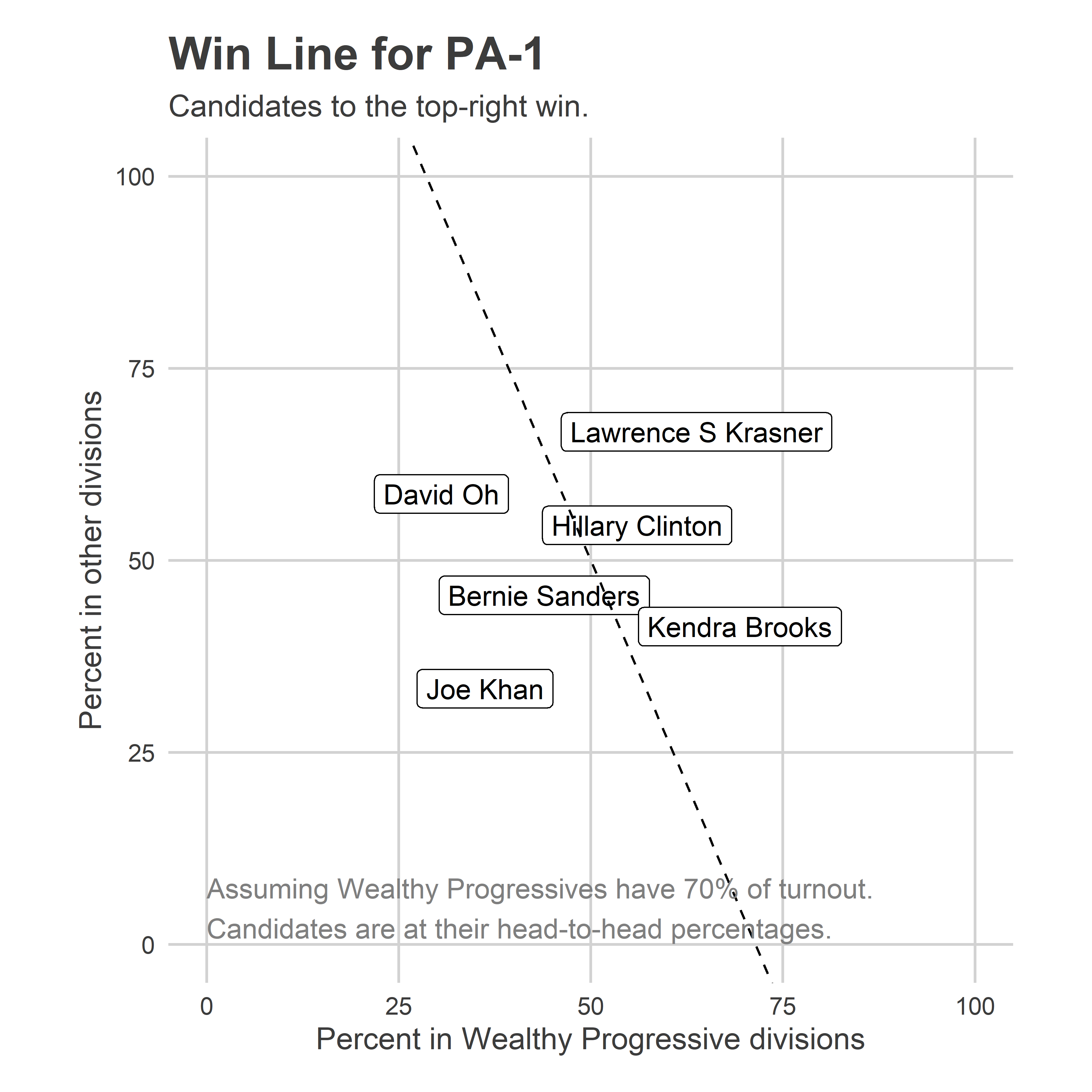
Need more? Create your own analyses on the Ward Portal!