New Year, New Elections
2020 is here. Finally.
While most eyes are on the Presidential race, the comparative advantage for my blog is going to be the state races. Can Democrats take back the Pennsylvania house? The Senate?
We’ll get to all that when the time comes. But first, let’s do spend some time talking about the April 28th Primary.
By the time Pennsylvania votes, 34 states will have already voted. There’s a good chance the Democratic nominee will be clear by then. But we’ve had competitive primaries here before, and with so many candidates in the running there’s a good chance no single candidate will have locked up the endorsement.
On Election Night, if it’s close, eyes will be focused on the Election Needle, especially now that we know it honest-to-goodness works. But the Needle is only built on Philadelphia returns. And I’m not going to try to process live data from each of 67 counties.
When you’re watching the Needle, and it’s certain who will win the city, what can you say about the state? Is it possible to predict Pennsylvania’s results knowing only Philadelphia’s returns? Clearly Philadelphia is significantly more urban and more liberal than the state as a whole, but within that we have pockets of different voters. Could those blocs give us insights to the state as a whole? Let’s dig in.
Pennsylvania’s voting bloc
The high-level strategy is to measure how the rest of the state’s counties correlates with Philadelphia’s blocs. I use the same SVD methodology that’s behind the Needle. All of my state data comes from the Open Elections Project.
We’ll consider the elections from 2004-2018. To measure the statewide correlations, we need statewide races, so we’ll limit the data to only Presidential and Gubernatorial races. And party primaries have entirely different correlations than generals, so we’ll filter to only competitive Democratic Primaries (excluding 2006 and 2018). The result is that we have data on five elections. That’s not great for understanding correlated random effects at the year level. But within years we have a lot of geographies, and within-year patterns emerge.
View code
library(dplyr)
library(tidyverse)
library(ggplot2)
library(sf)
library(magrittr)
library(cowplot)
source("../../admin_scripts/util.R")
counties <- st_read("../../data/gis/census/tigris_counties_2015.shp")col_names <- readLines("../../data/pa_election_data/openelections-data-pa-master/col_names.txt")
col_names <- strsplit(col_names, "(\\s)*(\\t)+")
col_names <- sapply(col_names, function(x) x[1])
col_names <- gsub(" ", "_", tolower(col_names))
col_names[2] <- "election_type"
read_open_elec_csv <- function(file){
read_csv(
file,
col_names = col_names
) %>%
select(
election_year, election_type, `county_code_*`, precinct_code,
candidate_district, `candidate_office_code_*`, `candidate_party_code*`,
candidate_last_name, candidate_first_name,
vote_total, fips_code
) %>%
rename(
candidate_party_code = `candidate_party_code*`,
candidate_office_code = `candidate_office_code_*`
)
}
get_open_elec_file <- function(year, election){
state_results_dir <- "../../data/pa_election_data/openelections-data-pa-master/"
year_dir <- sprintf("%s/%s", state_results_dir, year)
primary_file <- grep(
sprintf("[0-9]+__pa__%s__precinct\\.csv", election),
list.files(year_dir),
value=TRUE
)
file <- sprintf("%s/%s", year_dir, primary_file)
}
df_list <- list()
YEARS <- seq(2004, 2016, 2)
for(year in YEARS){
for(election in c("primary", "general")){
file <- get_open_elec_file(year, election)
df_list[[paste(year, election)]] <- read_open_elec_csv(file)
}
}
df_county <- bind_rows(df_list) %>%
mutate(
is_dem_primary = (election_type == "P" & candidate_party_code == "DEM"),
is_general_dem_rep = (election_type == "G" & candidate_party_code %in% c("DEM", "REP"))
) %>%
filter(
is_dem_primary | is_general_dem_rep,
candidate_office_code %in% c("USP", "GOV"),
!toupper(candidate_last_name) %in% c("WRITE-IN", "SCATTERED")
) %>%
group_by(
election_year, election_type, fips_code, candidate_party_code,
candidate_office_code, candidate_last_name, candidate_first_name
) %>%
summarise(votes = sum(vote_total))
df_pa <- df_county %>%
mutate(is_phila = (fips_code == "101")) %>%
group_by(
election_year, election_type, is_phila, candidate_party_code,
candidate_office_code, candidate_last_name, candidate_first_name
) %>%
summarise(votes = sum(votes)) %>%
group_by(
election_year, election_type, is_phila, candidate_office_code
) %>%
mutate(
is_competitive = n() > 1,
pvote = votes / sum(votes)
) %>%
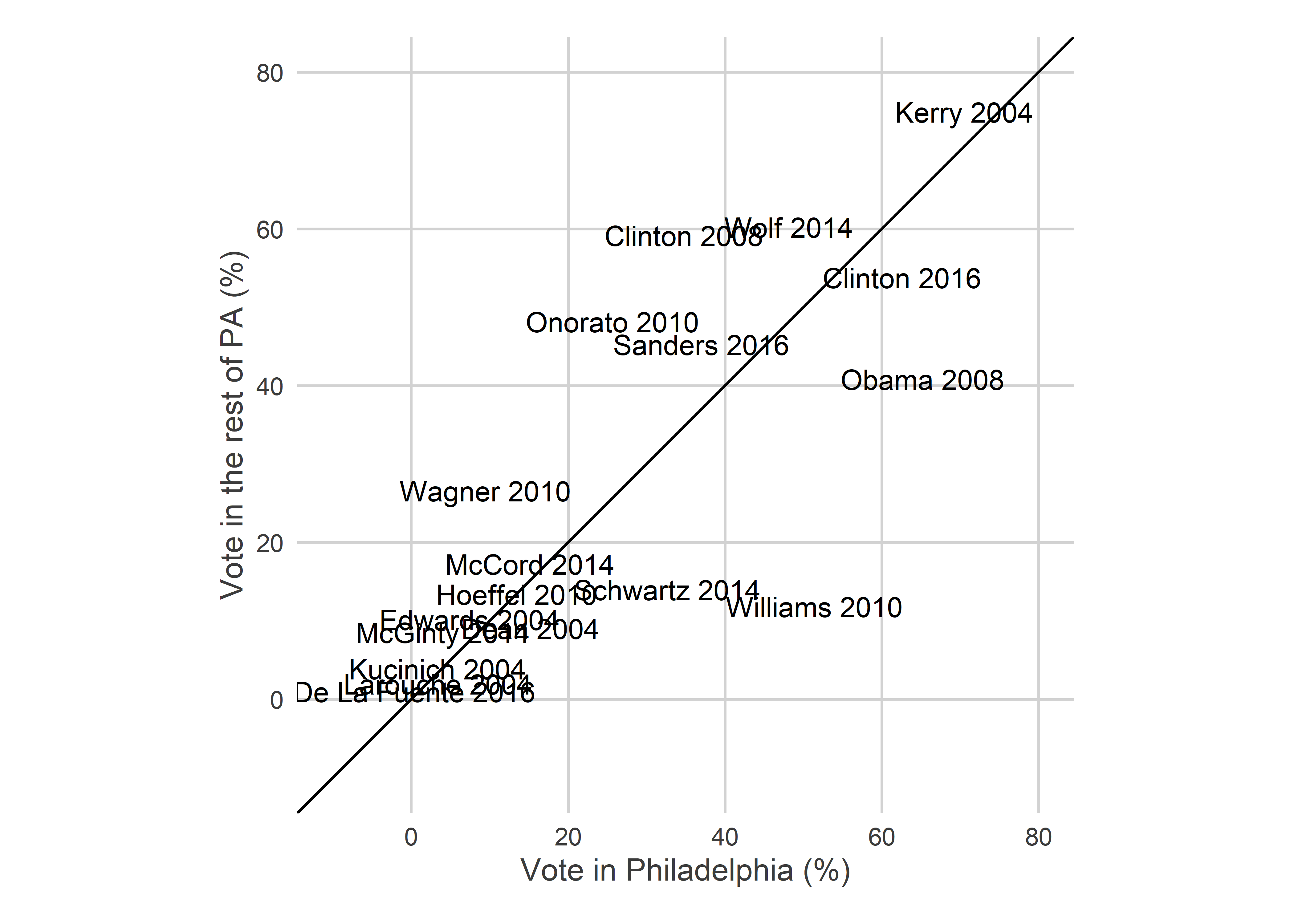
ungroup()Philadelphia’s results are broadly able to separate the candidates who are competitive in the rest of the state from those who aren’t. Among competitive candidates, the correlations are weaker; Obama won Philadelphia in 2008 but lost PA, Williams won Philadelphia in 2010 but Onorato won the state.
View code
ggplot(
df_pa %>%
filter(is_competitive, election_type == "P") %>%
gather(key="key", value="value", votes, pvote) %>%
mutate(key = sprintf("%s_%s", key, ifelse(is_phila, "phila", "pa"))) %>%
select(-is_phila) %>%
spread(key=key, value=value),
aes(x=100*pvote_phila, y=100*pvote_pa)
) +
geom_text(aes(label = sprintf("%s %s", format_name(candidate_last_name), election_year))) +
theme_sixtysix() +
coord_fixed() +
geom_abline(slope=1, intercept=0) +
expand_limits(x = c(-10,80), y=c(-10,80)) +
labs(
x="Vote in Philadelphia (%)",
y="Vote in the rest of PA (%)"
)
View code
df_major <- readRDS("../../data/processed_data/df_major_2019-12-03.Rds") %>%
mutate(warddiv = pretty_div(warddiv))
div_cats <- readRDS("../../data/processed_data/div_cats_2019-12-03.RDS")
df_divs <- df_major %>%
filter(
candidate != "Write In",
year %in% YEARS,
# (election == "general" & party %in% c("DEMOCRATIC", "REPUBLICAN")) | party == "DEMOCRATIC",
election == "primary", party == "DEMOCRATIC",
is_topline_office
) %>%
left_join(div_cats %>% select(warddiv, cat))
df_divs %<>%
mutate(
last_name = gsub(".*\\s(\\S+)$", "\\1", candidate),
last_name = ifelse(candidate == "LYNDON H LAROUCHE JR", "LAROUCHE", last_name),
last_name = ifelse(candidate == "ROQUE ROCKY DE LA FUENTE", "DE LA FUENTE", last_name)
)
assertthat::are_equal(
df_divs %>% select(last_name, year, election) %>%
unique() %>%
filter(!last_name %in% unique(df_pa$candidate_last_name)) %>%
nrow(),
0
)
df_phila <- df_divs %>%
group_by(year, election, last_name, cat) %>%
summarise(votes = sum(votes)) %>%
group_by(year, election, cat) %>%
mutate(
turnout = sum(votes),
pvote = votes/turnout,
election_type = toupper(substr(election, 1, 1))
) %>%
group_by(year, election) %>%
mutate(pct_turnout = turnout / sum(votes)) %>%
ungroup() %>%
select(-turnout) %>%
gather("key", "value", votes, pvote, pct_turnout) %>%
unite(key, key, cat, sep = "::") %>%
spread(key, value)View code
devtools::load_all("../svdcov")
divs <- st_read("../../data/gis/warddivs/201911/Political_Divisions.shp") %>%
mutate(warddiv = pretty_div(DIVISION_N)) %>%
st_transform(2272)counties <- st_transform(counties, 2272)
shp <- rbind(
counties %>%
select(GEOID, NAME, geometry) %>% mutate(level="county") %>%
filter(GEOID != "42101"),
divs %>% mutate(GEOID = warddiv) %>% rename(NAME = warddiv) %>% mutate(level="division") %>%
select(GEOID, NAME, geometry, level)
)
# ggplot(shp) + geom_sf()
df_all <- bind_rows(
df_county %>%
ungroup() %>%
filter(fips_code != "101") %>%
mutate(
GEOID = paste0("42", fips_code),
level="county"
) %>%
select(-candidate_first_name, -fips_code),
df_divs %>%
mutate(
candidate_office_code = c(GOVERNOR = "GOV", `PRESIDENT OF THE UNITED STATES` = "USP")[office],
candidate_party_code = substr(party, 1, 3),
election_type = toupper(substr(election, 1, 1)),
GEOID=warddiv,
candidate_last_name = last_name,
election_year = asnum(year),
level="division"
) %>%
select(
election_year, election_type, GEOID,
candidate_party_code, candidate_office_code, candidate_last_name,
votes, level
)
)
USE_LOG <- FALSE
if(USE_LOG){
transform_pvote <- function(x) log(x + 0.001)
transform_pvote_inv <- function(y) exp(y) - 0.001
} else {
transform_pvote <- identity
transform_pvote_inv <- identity
}
df_all <- df_all %>%
group_by(election_year, election_type, candidate_office_code) %>%
mutate(ncand = length(unique(candidate_last_name))) %>%
group_by(election_year, election_type, candidate_office_code, GEOID) %>%
mutate(pvote = votes / sum(votes)) %>%
group_by(election_year, election_type, candidate_office_code, candidate_last_name) %>%
mutate(state_votes = sum(votes)) %>%
group_by(election_year, election_type, candidate_office_code) %>%
mutate(state_pvote = state_votes / sum(votes)) %>%
ungroup() %>%
mutate(
target_demean = transform_pvote(pvote) - transform_pvote(1/ncand)
)
pvote_wide <- df_all %>%
## ONLY CONSIDER CANDIDATES WITH AT LEAST 5% OF STATEWIDE VOTE
filter(election_type == "P", state_pvote >= 0.05) %>%
unite("key", candidate_last_name, candidate_office_code, election_year, election_type) %>%
select(GEOID, key, target_demean) %>%
spread(key, target_demean, fill=transform_pvote(0) - transform_pvote(1/2))
pvote_mat <- as.matrix(pvote_wide %>% select(-GEOID))
rownames(pvote_mat) <- pvote_wide$GEOID
svd <- get_svd(
pvote_mat,
n_svd=4,
known_column_means=0,
verbose=FALSE,
method="svd"
)
cat_colors <- c(
`Black Voters` = light_blue,
`Wealthy Progressives` = light_red,
`White Moderates` = light_orange,
`Hispanic North Philly` = light_green,
`PA` = light_grey
)
score_means <- svd@row_scores %>%
left_join(
div_cats %>% select(warddiv, cat),
by=c("row" = "warddiv")
) %>%
mutate(
cat = ifelse(is.na(cat), "PA", as.character(cat)),
cat = factor(cat, levels=names(cat_colors))
) %>%
group_by(cat) %>%
summarise_at(vars(starts_with("score.")), list(mean)) %>%
gather("key", "value", starts_with("score")) %>%
mutate(
score_num = as.numeric(gsub("^score\\.([0-9])$", "\\1", key)),
value = value * svd@svd_d[score_num]
)
map_precinct_score <- function(svd, col, precinct_sf, adj_area=TRUE, geoid_col="warddiv"){
if(!is(svd, "SVDParams")) stop("params must be of class SVDParams")
precinct_sf$area <- as.numeric(st_area(precinct_sf))
if(adj_area){
if(svd@log){
adj_fe <- function(fe, area) fe - log(area)
} else {
adj_fe <- function(fe, area) fe / area
}
} else {
adj_fe <- function(x, ...) x
}
ggplot(
precinct_sf %>%
mutate(geoid = get(geoid_col)) %>%
left_join(svd@row_scores, by=c("geoid"="row"))
) +
geom_sf(
aes(fill = adj_fe(!!sym(col), area)),
color= NA
) +
scale_fill_viridis_c("Score")+
theme_map_sixtysix()
}
map_precinct_dim <- function(svd, k, precinct_sf, geoid_col="warddiv"){
map_precinct_score(
svd, paste0("score.",k), precinct_sf, adj_area=FALSE, geoid_col=geoid_col
) +
scale_fill_gradient2(
"Score",
midpoint = 0
)
}
for(k in 1:4){
min_score <- min(svd@row_scores[[sprintf("score.%s",k)]])
max_score <- max(svd@row_scores[[sprintf("score.%s",k)]])
state_map <- map_precinct_dim(svd, k, shp, geoid_col="GEOID") +
ggtitle(sprintf("Dimension %s", k)) +
theme(
legend.position="bottom", legend.direction="horizontal"
) +
guides(fill = FALSE) +
expand_limits(fill=c(min_score, max_score))
phila_map <- map_precinct_dim(
svd, k, shp %>% filter(level == "division"), geoid_col="GEOID"
) +
# ggtitle(sprintf("Philadelphia, Dimension %s", k)) +
expand_limits(fill=c(min_score, max_score)) +
theme(line=element_blank(), legend.position = c(0.7, 0.05))
print(
plot_grid(state_map, phila_map)
)
}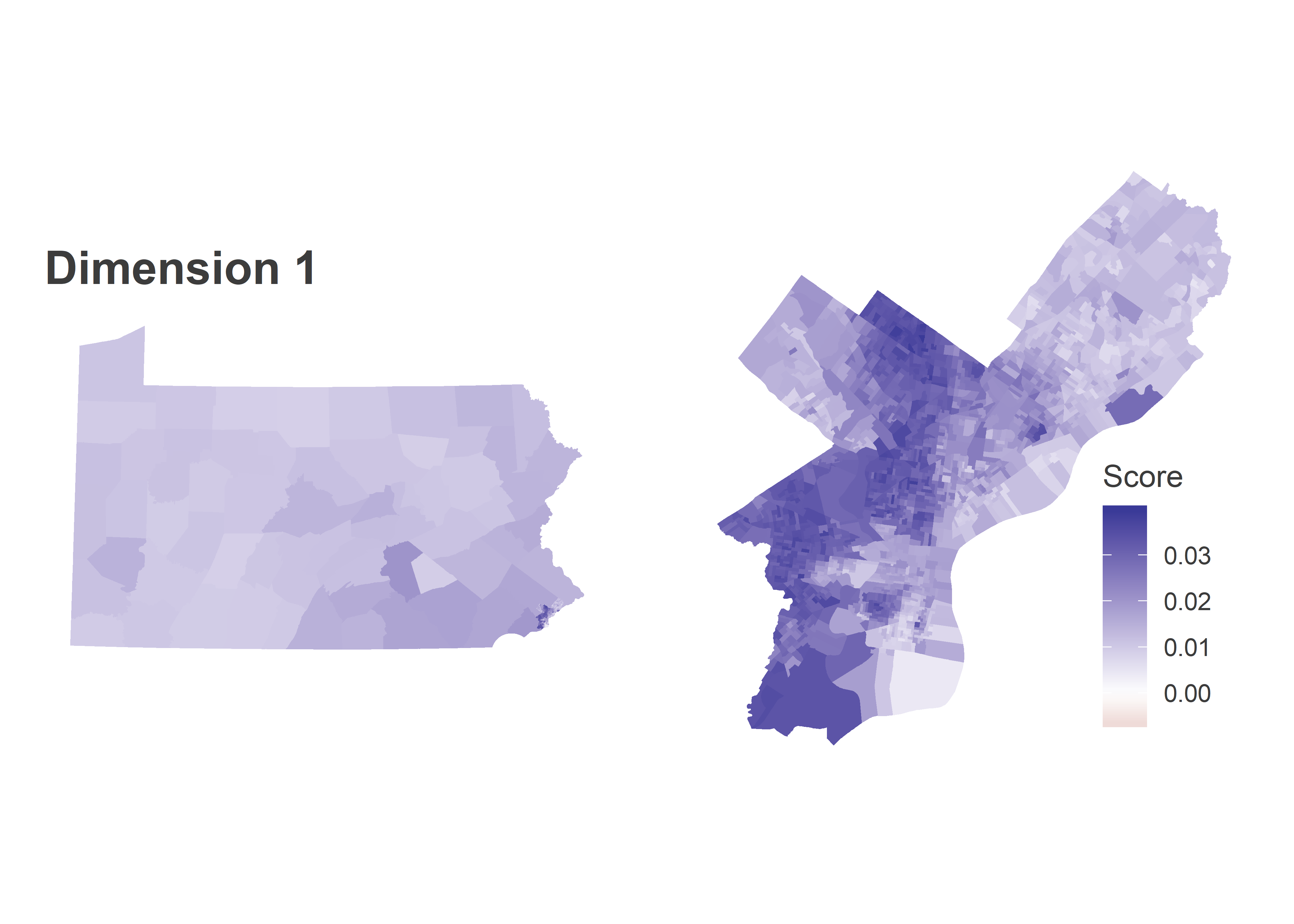
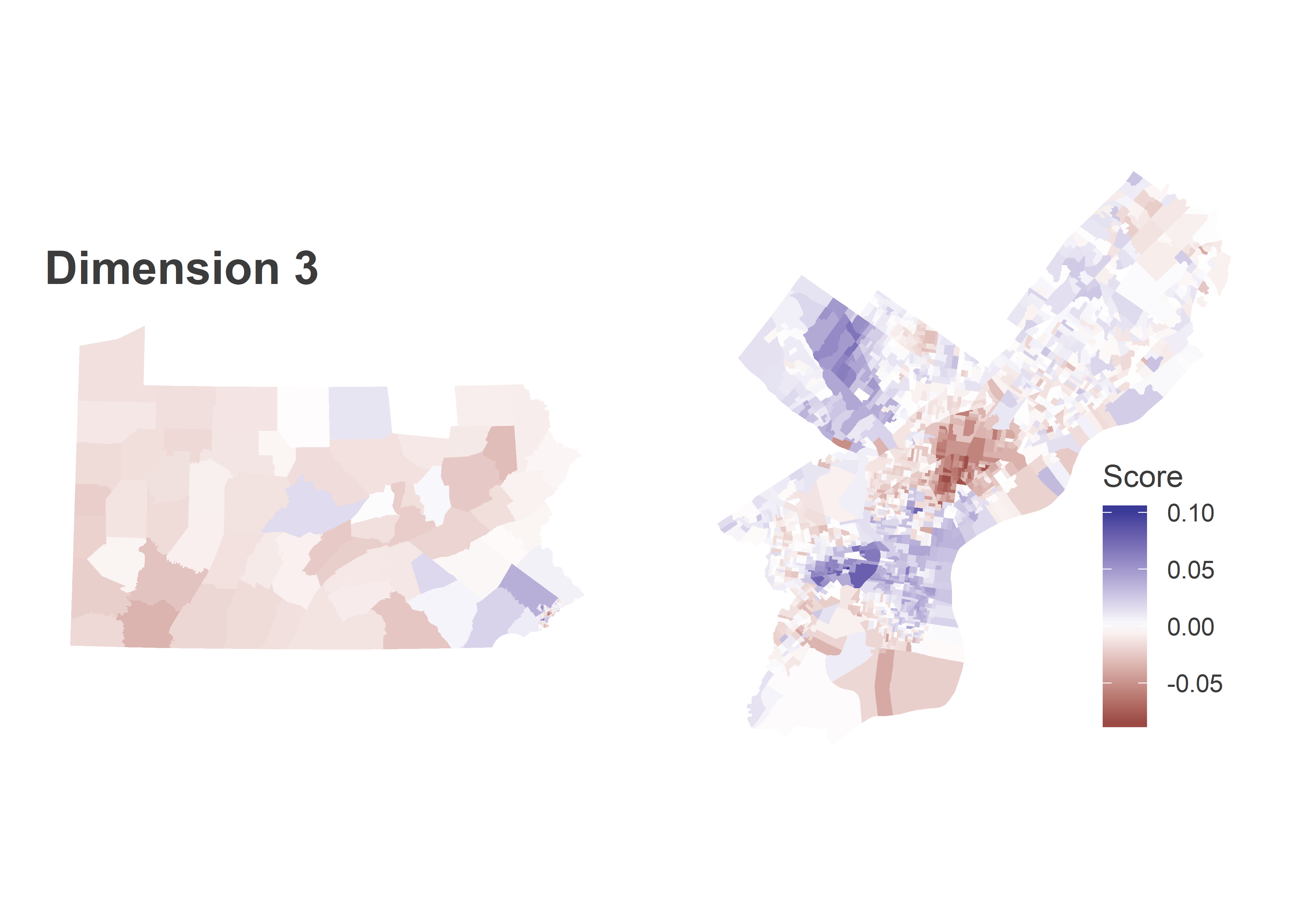
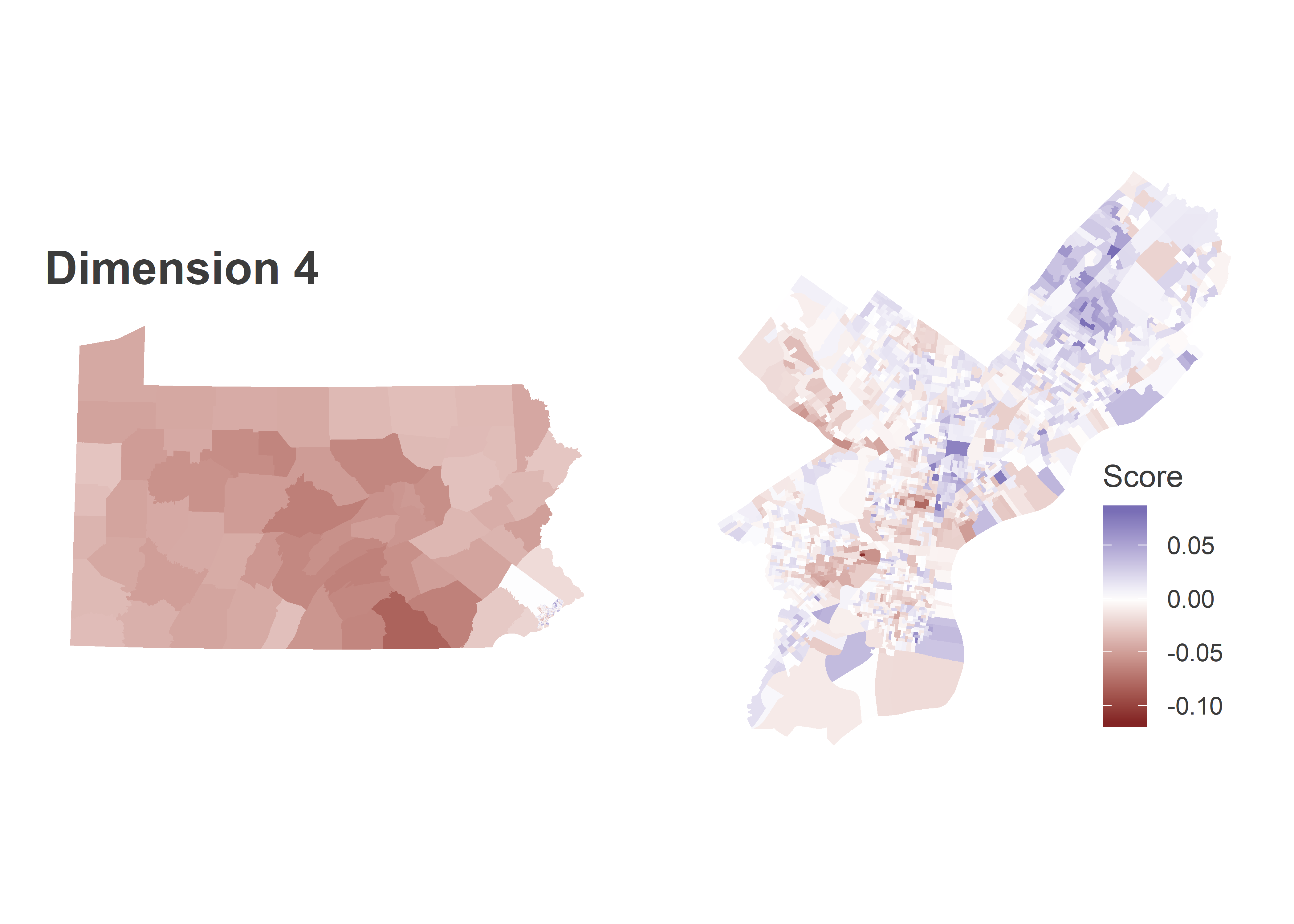
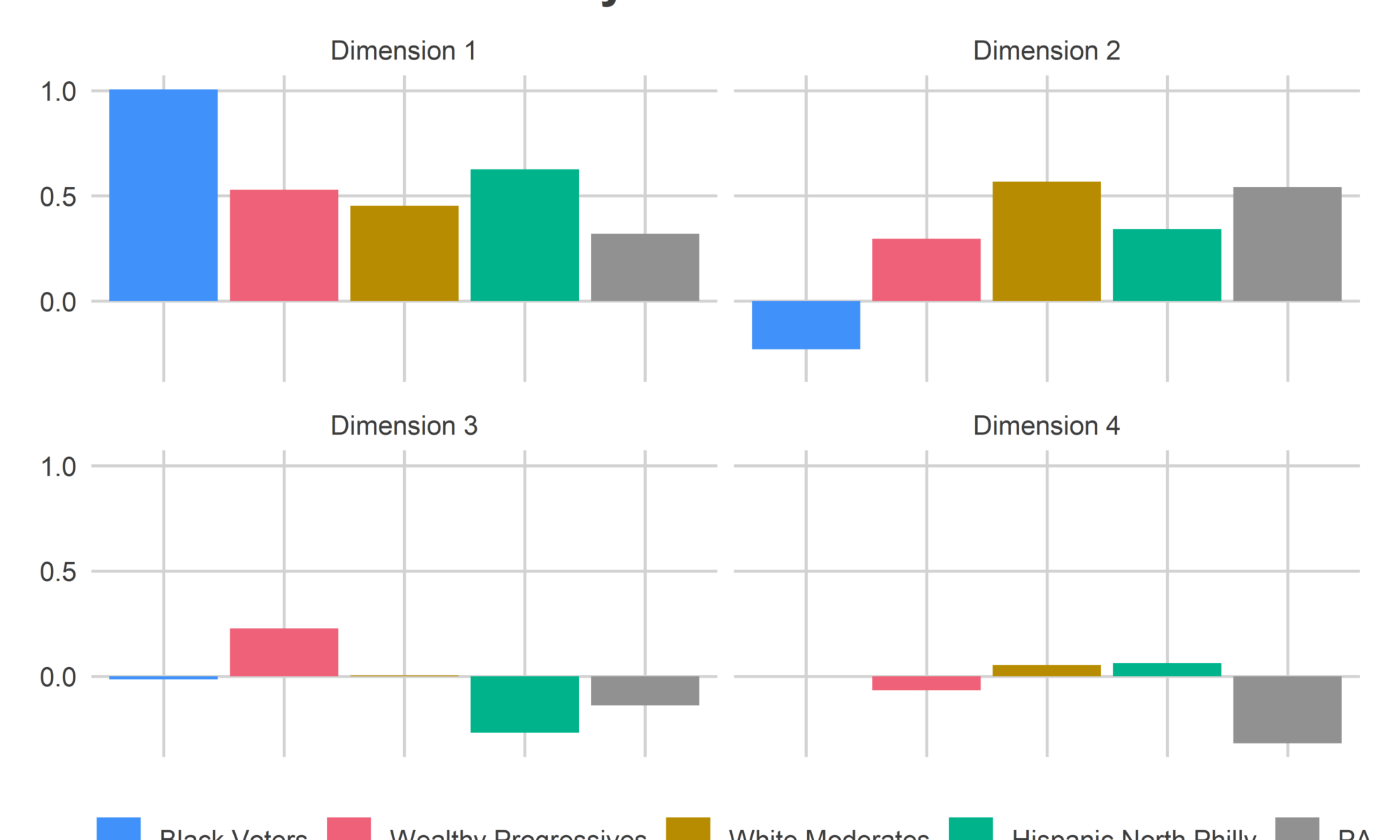
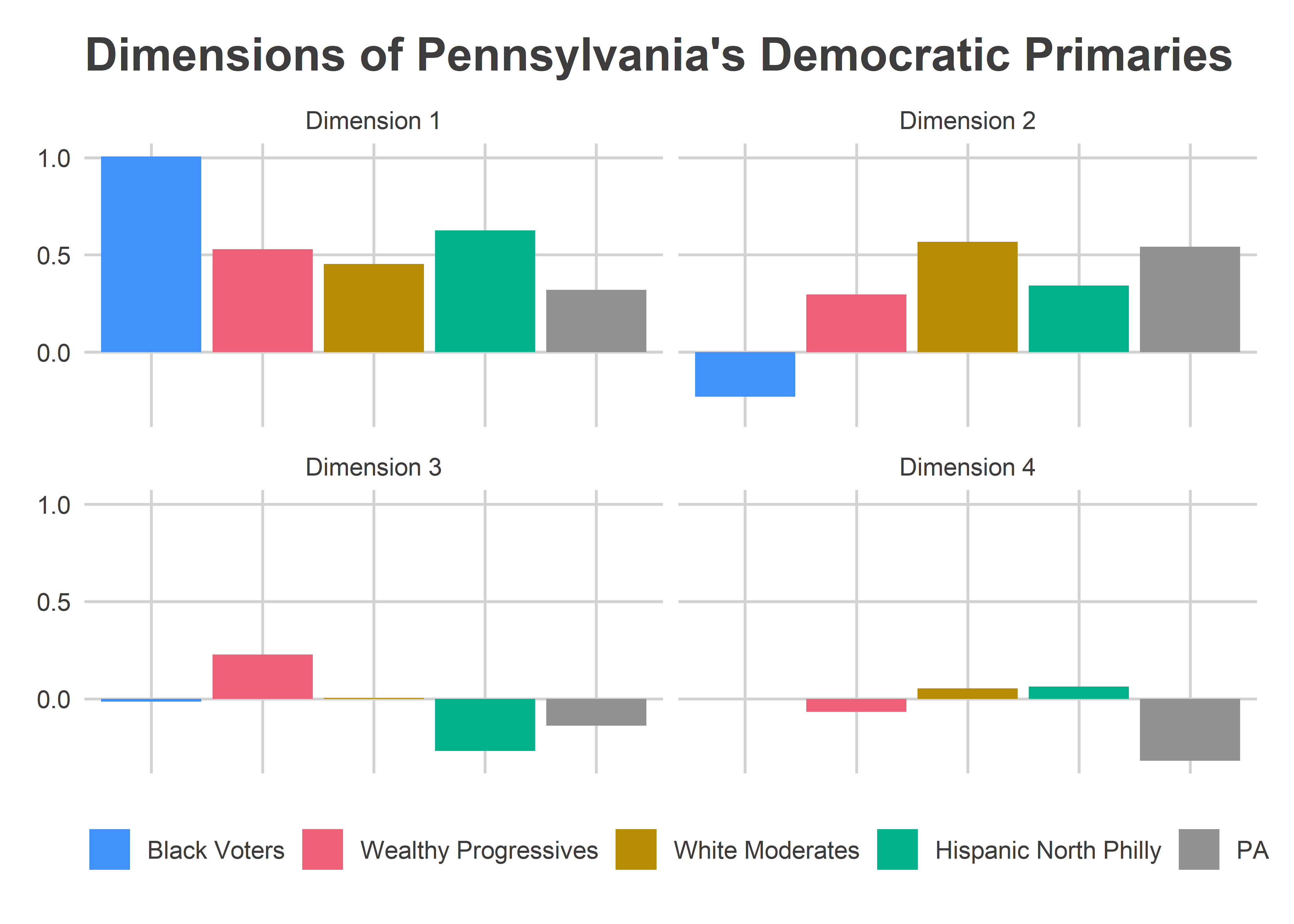
Dimension 1 is entirely blue, meaning when a candidate does better in one place, they do better everywhere. But within Philadelphia, the Black divisions of West and North Philly swing more for the popular candidates, and South-Eastern PA is swingier than the rest of the state. The table at the bottom of the post contains candidates’ scores in each dimension. Kerry (2004), Williams (2010), and Clinton (2016) had the most positive scores in this dimension (thought Williams had a large Dimension 2 score, so “broadly popular” may not be the right term).
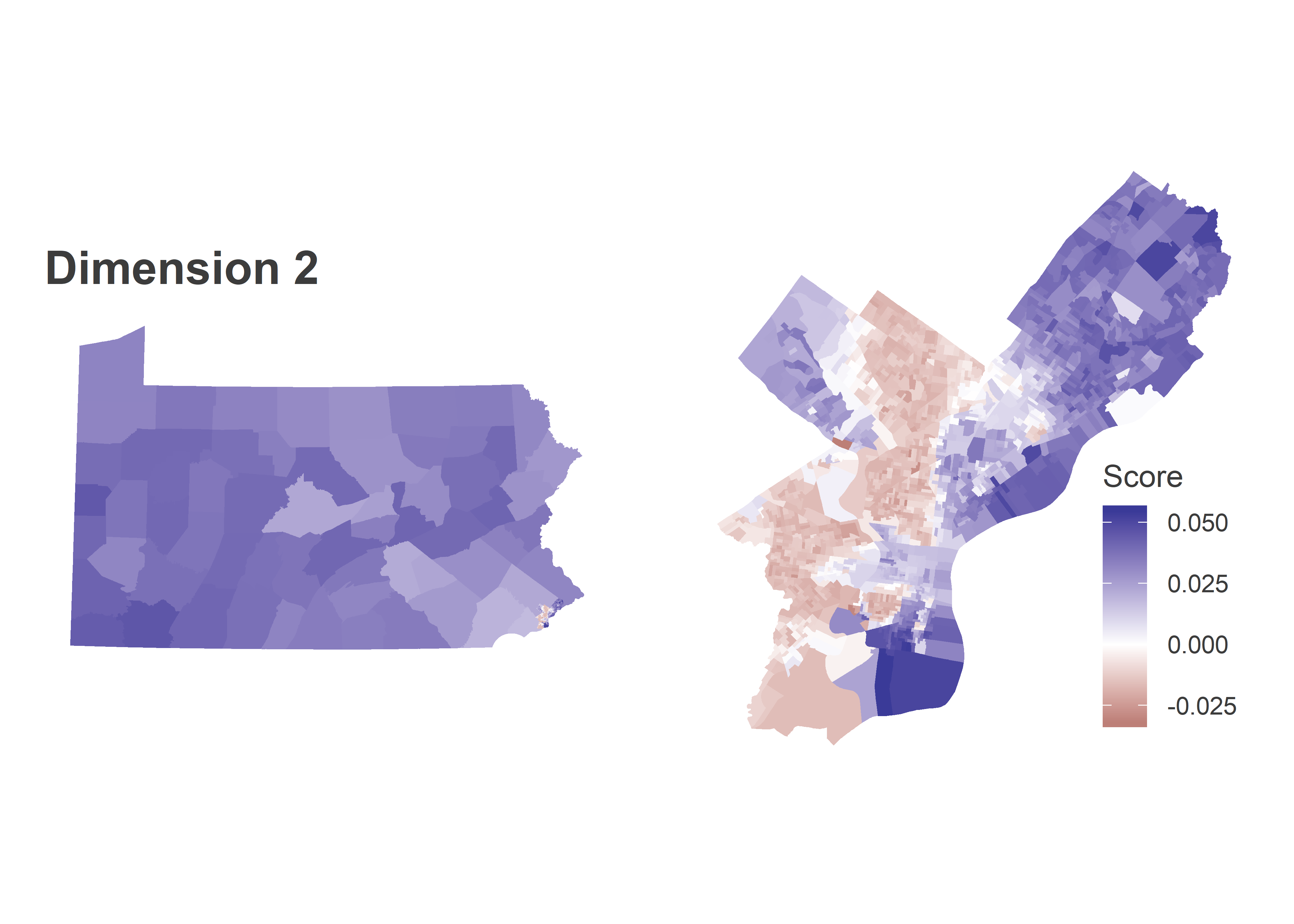
Dimension 2 identified Philadelphia’s racial divide. Candidates who did disproportionately well in the red regions were Obama (2008) and Williams (2010), candidates who did better in the blue regions were Clinton (2008) and Kerry (2004). The red Divisions are Philadelphia’s Black divisions, and the dark blue are Philadelphia’s White Moderates. The rest of the state looks a lot like the White Moderates along this dimension. The Philadelphia suburbs, including Delaware and Chester Counties, and State College’s Centre County are only light blues, meaning closer to the middle. Remember that this is only among Democratic Primaries, so this is a split within the party, and not Democratic-Republican. Also, many of the other counties would have red precincts within them if I used within-county measures instead of the county averages. But not everyone has historical data as clean as Philadelphia’s.
Dimension 3 finally introduces diversity in the rest of the state. Within Philadelphia, it divides the Wealthy Progressives (blue) from Hispanic North Philly (red). In the rest of the state, the Philadelphia suburbs and Centre County vote for similar candidates to the Wealthy Progressives, and the rest of Pennsylvania votes for similar candidates to Hispanic North Philly (these are typically broadly popular candidates.) Candidates who did disproportionately well in the blue regions were Obama (2008) and Hoeffel (2010), candidates who did well in the red were Wolf (2014) and Clinton (2008 and 2016).
Dimension 4 looks like noise within the city, but the rest of the state is deep red. It basically identifies candidates that split the state into Philadelphia versus everyone else. Wolf (2014) and Sanders (2016) have especially negative scores, and did disproportionately well in the rest of the state.
The below bar plot and candidate table illustrates the relationship between Philadelphia’s blocs and the rest of the state. To get a candidate’s predicted percent, you would take the candidate’s scores in each dimension, multiply by the region’s score, and sum across dimensions. So candidates with negative scores in a dimension do better in regions with negative scores in that dimension, and vice versa.
View code
ggplot(
score_means %>%
mutate(
key = sprintf("Dimension %s", gsub("score\\.([0-9])", "\\1", key))
),
aes(x = cat, y=value)
) +
geom_bar(aes(fill=cat), stat="identity") +
facet_wrap(~key) +
scale_fill_manual(values = cat_colors) +
theme_sixtysix() %+replace% theme(axis.text.x = element_blank()) +
labs(
y=NULL,
x=NULL,
fill=NULL,
title="Dimensions of Pennsylvania's Democratic Primaries"
)
View code
DT::datatable(
svd@col_scores %>%
select(-mean) %>%
separate(col, into = c("candidate", "office", "year","election")) %>%
mutate(candidate = format_name(candidate)) %>%
arrange(desc(score.1)) %>%
mutate_at(vars(starts_with("score")), function(x) sprintf("%0.3f", x)),
filter="none",
rownames=FALSE,
extensions = c("FixedColumns"),
options=list(
fixedColumns=TRUE,
scrollX=TRUE,
pageLength=nrow(svd@col_scores),
dom='t'
)
)The equation to predict the rest of the state
So, the rest of PA looks a lot like Philadelphia’s White Moderate divisions in all dimensions but Dimension 4. How should we aggregate up Philadelphia’s votes on election night?
I’ll use a totally different methodology that reassuringly gives qualitatively similar intuition. Let’s regress a candidate’s vote in the rest of the state on the vote coming out of Philadelphia’s blocs.
View code
df_lm <- df_pa %>%
filter(!is_phila) %>%
left_join(
df_phila %>% mutate(year = asnum(year)),
by = c(
"election_year" = "year",
"election_type" = "election_type",
"candidate_last_name" = "last_name"
)
) %>%
group_by(election_year, election_type) %>% mutate(ncand = n()) %>% ungroup
formula <- sprintf(
"pvote ~ ncand + %s",
paste0(
sprintf(
"`pvote::%s`",
c("Wealthy Progressives","Black Voters","White Moderates", "Hispanic North Philly")[-4]
),
collapse = " + ")
)
fit <- lm(
as.formula(formula),
data = df_lm
)
# summary(fit)
## Proportions of votes
df_all %>%
filter(election_type == "P", candidate_party_code == "DEM") %>%
group_by(election_year, candidate_office_code, level) %>%
summarise(votes = sum(votes)) %>%
group_by(election_year) %>%
mutate(pct = votes / sum(votes))
df_divs %>%
group_by(year, election, cat) %>%
summarise(votes = sum(votes)) %>%
group_by(year, election) %>%
mutate(pct = votes / sum(votes)) %>%
select(-votes) %>%
spread(key=cat, value = pct)We don’t have a ton of races. Worse, within each year candidates’ results are correlated with each other. This all means I don’t have much faith in the standard errors of the estimates. But at a high level, the results seem sane. Treat this like a rule of thumb, rather than rigorous analysis.
To predict the vote in the rest of the state, the formula is
Pct(Rest of PA) = 0.75 * Pct(White Moderates) + 0.33 * Pct(Wealthy Progressives) – 0.08 * Pct(Black Voters).
Candidates who do better in Philadelphia’s Black divisions actually do worse in the rest of the state, holding constant their results in the Whiter divisions.
Philadelphia accounts for about 20% of the state’s votes in the Democratic Primary, so if we add in those votes to get the combined results of Philadelphia plus the rest of the state (using the proportions that Philadelphia’s turnout is 53% Black Voters, 20% Wealthy Progressives, 23% White Moderates, 4% Hispanic North Philly),
Pct(State-Wide) = 0.65 * Pct(White Moderates) + 0.30 * Pct(Wealthy Progressives) + 0.04 * Pct(Black Voters) + 0.01 * Pct(Hispanic North Philly).