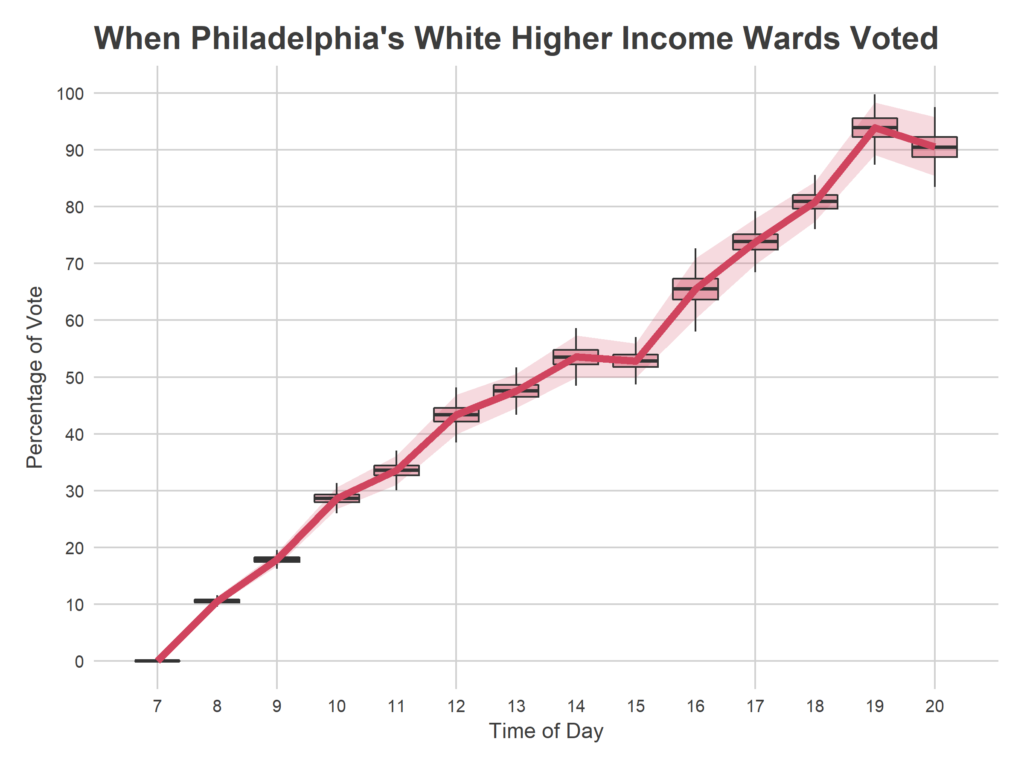
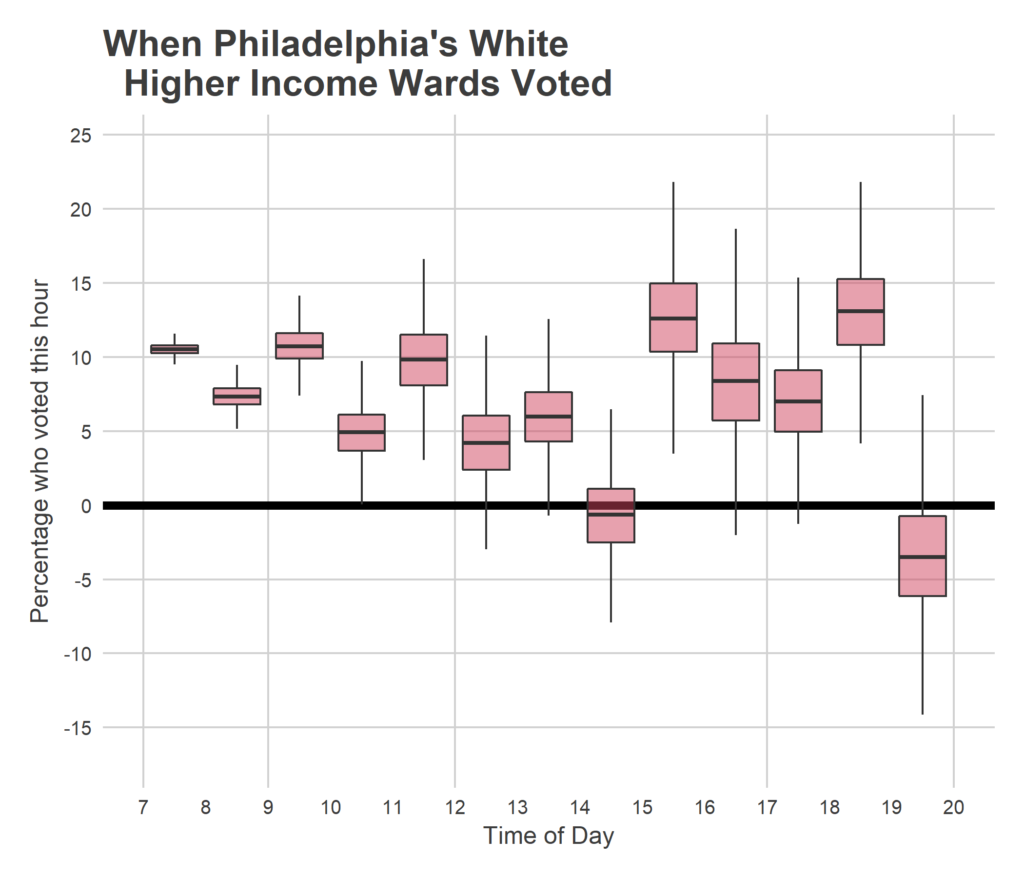
Pennsylvania has important state and local races as well. Voters here will be choosing a Governor and Senator, in two elections where Democratic incumbents are well-positioned. How about the down-ballot races? Could the Pennsylvania House of Representatives be in play?
The Pennsylvania House has been solidly Republican since 2010, and has had a Republican majority for 20 out of the last 24 years. In 2016, 121 Republicans won versus 82 Democrats. Of those races, 51 were uncontested Republicans, and 47 uncontested Democrats.
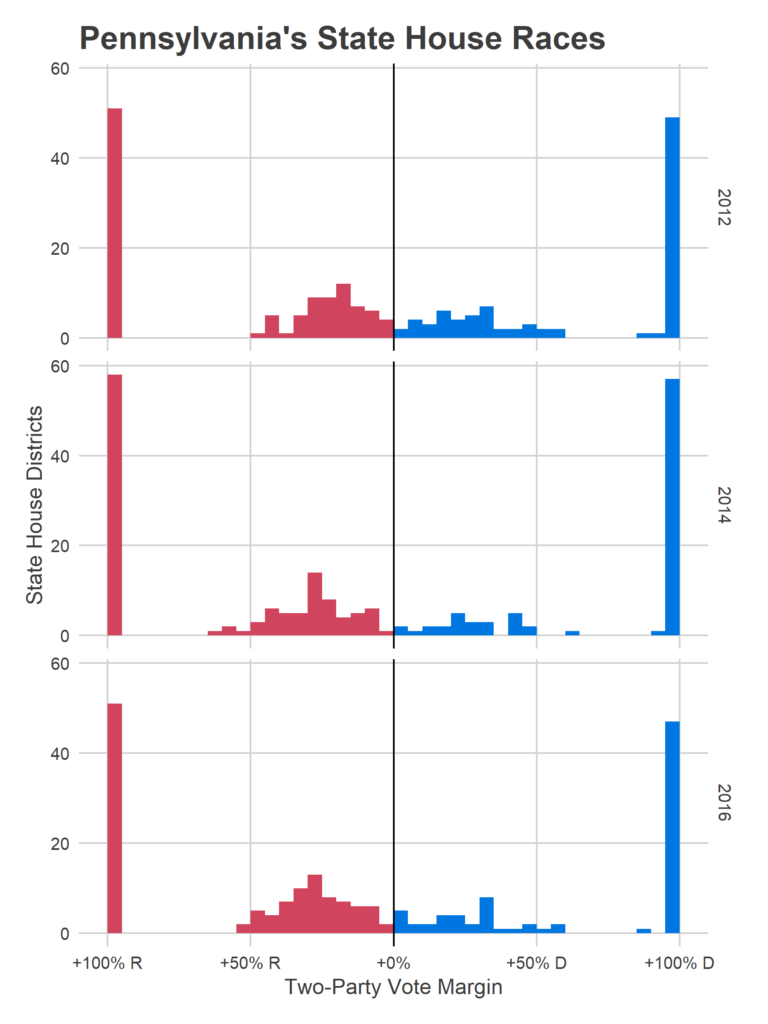
Philadelphia is vitally important in this picture. Some 13 of those Republican districts within 16 points are in Philadelphia or its four-county suburbs.
A surge of that size is probably not going to happen, but it shows what’s in play. These hyper-local races probably benefit from very strong incumbency, and it’s unclear how national signals will translate.
Pennsylvania has 19 districts with a Republican representative that was won by Hillary Clinton. Stunningly, every single one of them is in Philadelphia or its suburbs. And in two of those Democrats didn’t even field a candidate. If Donald Trump has nationalized the election, and energizes Democratic voters, Democrats could capitalize on this anti-Trump sentiment.
Finally, let’s look at the raw data for the districts. To make this manageable, I’ve broken them into chunks based on whether the primaries were contested, party of the Representative, and 2016 Presidential results. Below, I present each district’s 2016 results (as the two-party vote, meaning excluding third parties and non-votes), and turnout in the 2014 and 2018 primaries.
First, the 39 districts that the Democrats didn’t contest in 2016 but now have a candidate, including two that Hillary won.
What do we make of all this? Unfortunately, it’s unclear how this election will break. Are the districts that voted for a Republican Representative but Clinton in 2016 more likely to swing towards the Democrats, given the first two years of Trump’s presidency, or will they continue to support the incumbent, especially with Trump not on the ballot? Will the districts with primary surges show up? How important is the fact that Democrats have fielded candidates in 39 districts that went uncontested in 2016, and can that shift turnout there in ways that change the Governor’s race?
As the summer comes to a close, I’ll be looking at a few of these Philadelphia-area races, and trying to understand the landscape for November.